--Thanks to all the creators especially Clowwindy!
[toc]
概述
在阅读了shadowsocks的源码中,我学习到了以下几部分重要内容,包括且不限于:
- 基于事件编程的编程模式及回调函数的概念和应用
- 网络编程的I/O模型-特别是 I/O 多路复用的Reactor反应器模型
- 守护进程的处理
- 配置文件的读取及处理
- 进一步了解了加密算法 将之前看过的密码学概述[^1]与实际应用相结合
- 加深理解了代理服务器的概念
- 对数据结构的初窥门径
- 超时事件的处理
基于事件的编程模式
事件的分发
事件驱动程序设计(英语:Event-driven programming)是一种电脑程序设计模型。这种模型的程序执行流程是由用户的动作(如鼠标的按键,键盘的按键动作)或者是由其他程序的消息来决定的。相对于批处理程序设计(batch programming)而言,程序执行的流程是由程序员来决定。批处理(batch)的程序设计在初级程序设计教学课程上是一种方式。然而,事件驱动程序设计这种设计模型是在交互程序(Interactive program)的情况下孕育而生的。[^2]
取代传统上一次等待一个完整的指令然后再做执行的方式,事件驱动程序模型下的系统,基本上的架构是预先设计一个事件循环所形成的程序,这个事件循环程序不断地检查目前要处理的信息,根据要处理的信息执行一个触发函数(回调函数)进行必要的处理。其中这个外部信息可能来自一个目录夹中的文件,可能来自键盘或鼠标的动作,或者是一个时间事件。
在作为网络代理软件的shadowsocks中,采用了基于事件的编程的方法,特别是反应器(Reactor)设计模式。其中,出现的事件主要有欢迎套接字有入连接,连接套接字的可读可写或错误,DNS请求得到回应。事件的注册是封装了select.epoll().register(fd[, eventmask])方法;事件的接收是封装了select.epoll().poll(timeout)方法,会返回一个列表,每个元素是一个元组,元组包含两个值:就绪的文件描述符和事件信息:
- 文件描述符(fileno):表示有事件发生的文件描述符。
- 事件掩码(event mask):表示该文件描述符上发生的事件类型。
在得到发生事件的列表后,就调用各事件注册的触发函数(回调函数),对该事件进行处理。
增加监听事件和返回发生事件,在程序中是如下实现的(在eventloop.py的EventLoop类内方法定义中):
def poll(self, timeout=None):
events = self._impl.poll(timeout) #select.epoll().poll(timeout) 是使用 epoll 机制进行 I/O 多路复用的操作,用于检测注册的文件描述符上是否有事件发生 最多等timeout秒
#如果在这段时间内有注册的文件描述符上发生了事件,则立即返回一个列表,其中包含发生事件的文件描述符及其对应的事件类型。
return [(self._fdmap[fd][0], fd, event) for fd, event in events] #[fd][0]是add中的第一个参数f,是由文件描述符找的对应套接字
def add(self, f, mode, handler):#f可以是套接字 看作文件 handler直接传进去了DNSResolver类的对象
fd = f.fileno()#文件描述符 套接字获得
self._fdmap[fd] = (f, handler) #文件描述符映射处理器的handler 实际上是各个类如tcprelay 调用handler.handleevent
self._impl.register(fd, mode)#将文件描述符注册到 epoll 对象中以便进行事件监听。mode是关注什么事件 不同阶段 注册不同的事情 只注册一个关注的事情
值得注意的是,register()方法注册的是文件描述符,poll()方法返回也是文件描述符,而不是直接的套接字。在封装poll()和register()方法时,作者对套接字进行了特殊的处理:对套接字与其对应的回调函数与文件描述符的映射进行了记录 ,储存到self._fdmap = {} # (f, handler)注册事件。这样的实现,就可以直接在poll()获取事件时,直接从fd找到对应的套接字及相应的回调函数。去掉异常处理相关代码,获取事件处理事件代码如下:
events = self.poll(TIMEOUT_PRECISION)#默认等无限 这里等10s 超时返回0
for sock, fd, event in events:
handler = self._fdmap.get(fd, None)#通过映射拿到回调函数
if handler is not None:
handler = handler[1]#其中handler[1]是(f, handler)中的后者,实际是TCPRelay、UDPRelay和DNSResolver的实例
handler.handle_event(sock, fd, event)#就是调用TCPRelay、UDPRelay和DNSResolver实例的handle_event(sock, fd, event)方法
所有的事件都由loop=eventloop.EventLoop()一个实例处理,无论是DNS套接字相关的,TCP欢迎套接字相关的,TCP连接套接字相关的以及UDP相关套接字相关的。其分发关系如下,图来自Shadowsocks 源码分析——协议与结构 (loggerhead.me):
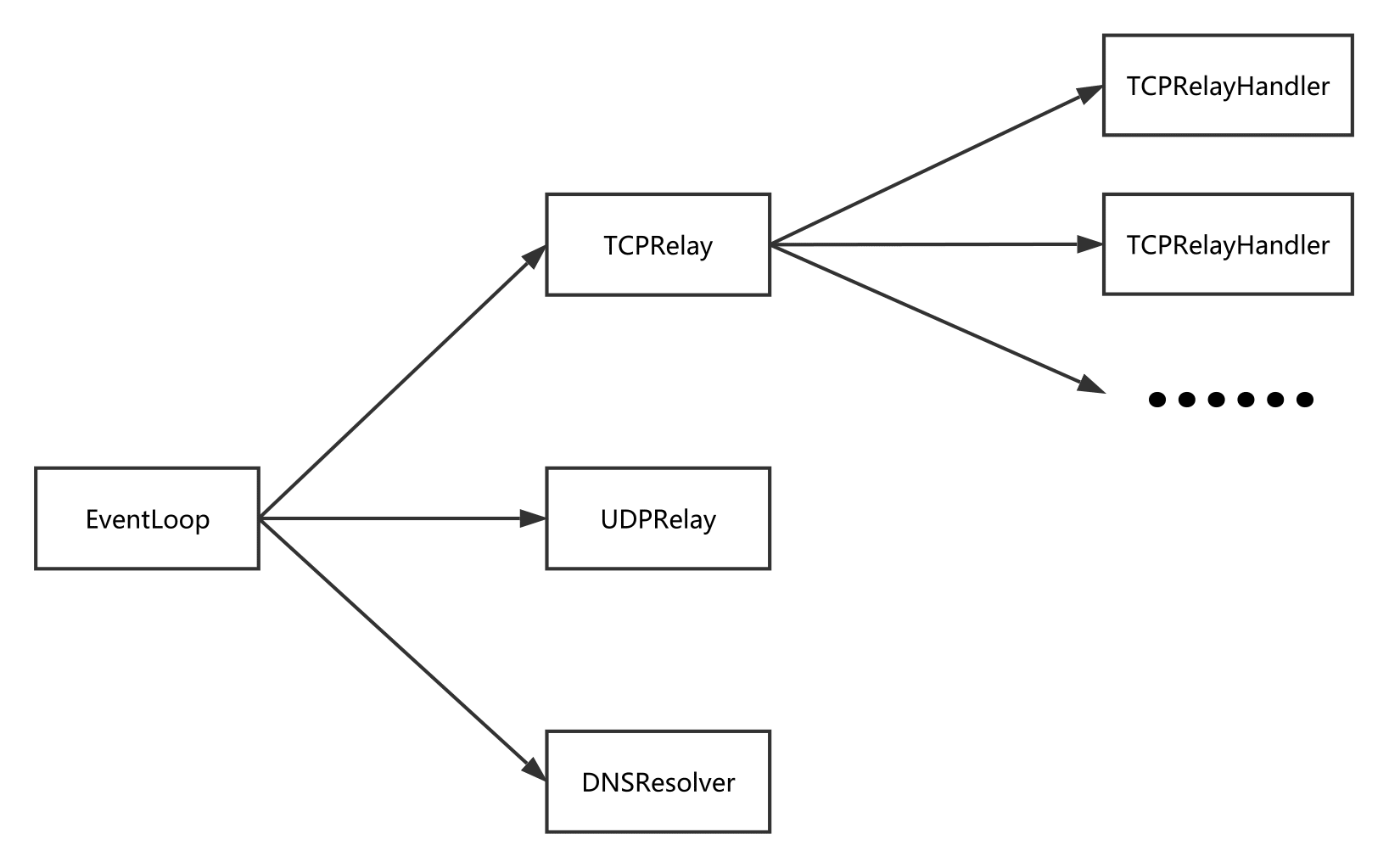
在初看此图时,不理解TCPRelayHandler为什么在TCPRelay之后,读完后大概理解了:为了方便管理超时连接。具体将在超时管理部分详细写出。而TCPRelayHandler在构造函数初始化时,向loop注册事件,会将TCPRelay的实例作为回调函数,也就是第三个参数传过去:
`loop.add(local_sock, eventloop.POLL_IN | eventloop.POLL_ERR,self._server)#把tcprelay作为处理器传过去 再分发 #监听POLL_IN可读事件开始的`self.server的赋值在构造函数时给出:
def __init__(self, server, fd_to_handlers, loop, local_sock, config,dns_resolver, is_local): self._server = server
在TCPRelay的handle_event方法中,欢迎套接字收到请求建立连接套接字时,会初始化一个TCPRelayHandler实例,其中self是这个TCPRealy的实例,作为第一个参数传入。这样就将TCPRelayHandler在loop中的事件注册器注册成了TCPRelay的实例,可以加深上述两行程序的理解。
TCPRelayHandler(self, self._fd_to_handlers,self._eventloop, conn[0], self._config,self._dns_resolver, self._is_local)
那么这样的话,当TCPRelayHandler相关的套接字(实际上TCPRelayHandler最终会负责两个套接字的事件,一个是刚刚提到的本地应用程序到sslocal的连接套接字,另一个是要和ssserver建立连接的另一条套接字)发生事件时,loop会将发生事件的套接字(通过loop._fdmap)、文件描述符和事件都传给TCPRelay.handle_event方法,在这个过程中,TCPRelay通过查询自己维护的_fd_to_handlers,将发生事件的套接字和事件类型传给对应的TCPRelayHandler的handle_event方法,从而完成图片中右侧箭头的各个TCP连接事件处理的二次分发。
事件的处理
我们关注一条TCP连接通过shadowsocks代理时的细节,不涉及udp代理,因此我们下一步分析DNSResolver、TCPRelay和TCPRelayHandler的handle_event方法。
首先是DNSResolver:
class DNSResolver(object):
def handle_event(self, sock, fd, event):#针对不同情况写不同的事件处理
if sock != self._sock:
return
if event & eventloop.POLL_ERR:
logging.error('dns socket err')
self._loop.remove(self._sock)
self._sock.close()
# TODO when dns server is IPv6
self._sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM,
socket.SOL_UDP)
self._sock.setblocking(False)
self._loop.add(self._sock, eventloop.POLL_IN, self)#重新加
else:
data, addr = sock.recvfrom(1024)
if addr[0] not in self._servers:#是发出DNS请求的上游DNS服务器地址
logging.warn('received a packet other than our dns')
return
self._handle_data(data)#这是收到回复数据的处理
当DNS相关的udp套接字发生事件,被loop的poll方法调用DNSResolver实例的handle_event方法。在判断套接字确实是这个DNS相关的udp套接字时,如果是套接字返回了错误就关闭重新建立,如果收到了数据且判断确实是我们设定的上游DNS服务器(如谷歌的8.8.8.8,由self.servers指定),那么就处理收到的数据包,_handle_data函数实际上是解析上游DNS服务器返回的ipv4或ipv6地址,如果这个域名在待解析的列表中(没有超时被删除),则调用对应TCPRelayHandler的回调函数,通知TCPRelayHandler与远端进行套接字连接。这里的说明并不具体,只是为了让整个事件的过程形容的比较完整,降低回顾程序时的难度,详细的内容会在其他部分说明,如果写到后面了想起来会在这里补充。
其次是TCPRelay:
class TCPRelay(object):
def handle_event(self, sock, fd, event):#eventloop的add方法会将套接字映射成文件描述符在loop的_fdmap方法中_fdmap[fd]就是套接字sock
# handle events and dispatch to handlers
if sock:
logging.log(shell.VERBOSE_LEVEL, 'fd %d %s', fd,
eventloop.EVENT_NAMES.get(event, event))#不在返回event本身
if sock == self._server_socket:#新连接来了
if event & eventloop.POLL_ERR:
# TODO
raise Exception('server_socket error')
try:
logging.debug('accept')
conn = self._server_socket.accept()#接受 也就是tcp三次握手中的第二个回程发送以及第三个收到ack 之后返回进行下一步 conn是连接套接字
#TCPRelayHandler的构造函数原型def __init__(self, server, fd_to_handlers, loop, local_sock, config,dns_resolver, is_local):
TCPRelayHandler(self, self._fd_to_handlers,
self._eventloop, conn[0], self._config,
self._dns_resolver, self._is_local)
#144行的 self._loop.add(remote_sock, eventloop.POLL_ERR, self._server)
#tcprelayhandler的注册时 初始化第一个参数会作为_server注册事件处理 这里传进去的是tcprelay类
#也就是说 tcprelayhandler的事件 最先调用的处理器 是tcprelay的处理器
except (OSError, IOError) as e:
error_no = eventloop.errno_from_exception(e)
if error_no in (errno.EAGAIN, errno.EINPROGRESS,
errno.EWOULDBLOCK):
return
else:
shell.print_exception(e)
if self._config['verbose']:
traceback.print_exc()
else:
if sock:#连接套接字 tcprelayhandler
handler = self._fd_to_handlers.get(fd, None)#文件描述符注册了对应的处理器
if handler:
handler.handle_event(sock, event)
else:
logging.warn('poll removed fd')
TCPRelay实例的handle_event方法被调用时,会先判断分发过来的套接字是不是欢迎套接字,如果是,就接收连接,并生成一个TCPRelayHandler实例用来处理这个连接套接字,在这个过程中也会将负责事件循环的loop,配置文件(用来检查这个TCPRelayehandler要转发的远端是不是在禁止ip列表中),文件描述符和套接字的映射字典(用于TCPRelayehandler将远端的套接字和文件描述符也放入字典)等作为TCPRelayHandler构造函数参数传入。如果不是,就通过文件描述符和套接字的映射字典_fd_to_handlers查询这个套接字对应那个连接(TCPRelayehandler),并调用该TCPRelayehandler实例的回调函数。
最后是TCPRelayHandler:
class TCPRelayHandler(object):
def handle_event(self, sock, event):
# handle all events in this handler and dispatch them to methods
if self._stage == STAGE_DESTROYED:
logging.debug('ignore handle_event: destroyed')
return
# order is important
if sock == self._remote_sock:
if event & eventloop.POLL_ERR:
self._on_remote_error()
if self._stage == STAGE_DESTROYED:
return
if event & (eventloop.POLL_IN | eventloop.POLL_HUP):
self._on_remote_read()
if self._stage == STAGE_DESTROYED:
return
if event & eventloop.POLL_OUT:
self._on_remote_write()
elif sock == self._local_sock:
if event & eventloop.POLL_ERR:
self._on_local_error()
if self._stage == STAGE_DESTROYED:
return
if event & (eventloop.POLL_IN | eventloop.POLL_HUP):
self._on_local_read()
if self._stage == STAGE_DESTROYED:
return
if event & eventloop.POLL_OUT:
self._on_local_write()
else:
logging.warn('unknown socket')
TCPRelayHandler实例的handle_event方法被调用时,会检查是近端(_local_sock)/远端(_remote_sock)套接字发生了可读(POLL_IN)/可写(POLL_OUT)事件,进而调用不同的函数。
| 情况判断 | 调用函数 |
|---|---|
| 近端套接字发生了可写事件 | _on_local_write() |
| 近端套接字发生了可读事件 | _on_local_read() |
| 远端套接字发生了可写事件 | _on_remote_write() |
| 远端套接字发生了可读事件 | _on_remote_read() |
_on_remote_read()和_on_local_read()都是从对应的套接字读取数据完成加解密并尝试写入另一端,并包含了无法一次性全部写入另一端套接字的处理,以实现转发数据的功能。_on_remote_write()和_on_local_write()都是从缓存区读取剩下的待发送的数据,将其写入对应的套接字,可以说_on_remote_write()和_on_local_write()是前面两个_on_xxx_read数据过长无法一次完成时,补充二次写入的函数。一次无法完全写入的原因有运输层协议TCP的缓存区设计以及socket.recv()的设计,其中socket.recv()还涉及到epoll的水平触发概念,有兴趣的请自行查阅。
到这里有一点需要注意,TCPRelay和DNSResolver的handle_event的函数原型(接口)是(self, sock, fd, event),而TCPRelayHandler的函数原型是(self, sock, event)。这是因为前者由loop调用,后者由TCPRelay调用。这说明了回调函数的一个特性:被调用方(函数定义方)和调用方(通知事件方)要做好一致性沟通,这样被调用方将自身的回调函数在调用方进行注册,调用方就可以通过这个原型将相关参数输入,完成发生事件后的通知和处理。在这个shadowsocks例子中,以loop和TCPRelay的相关关系为例:
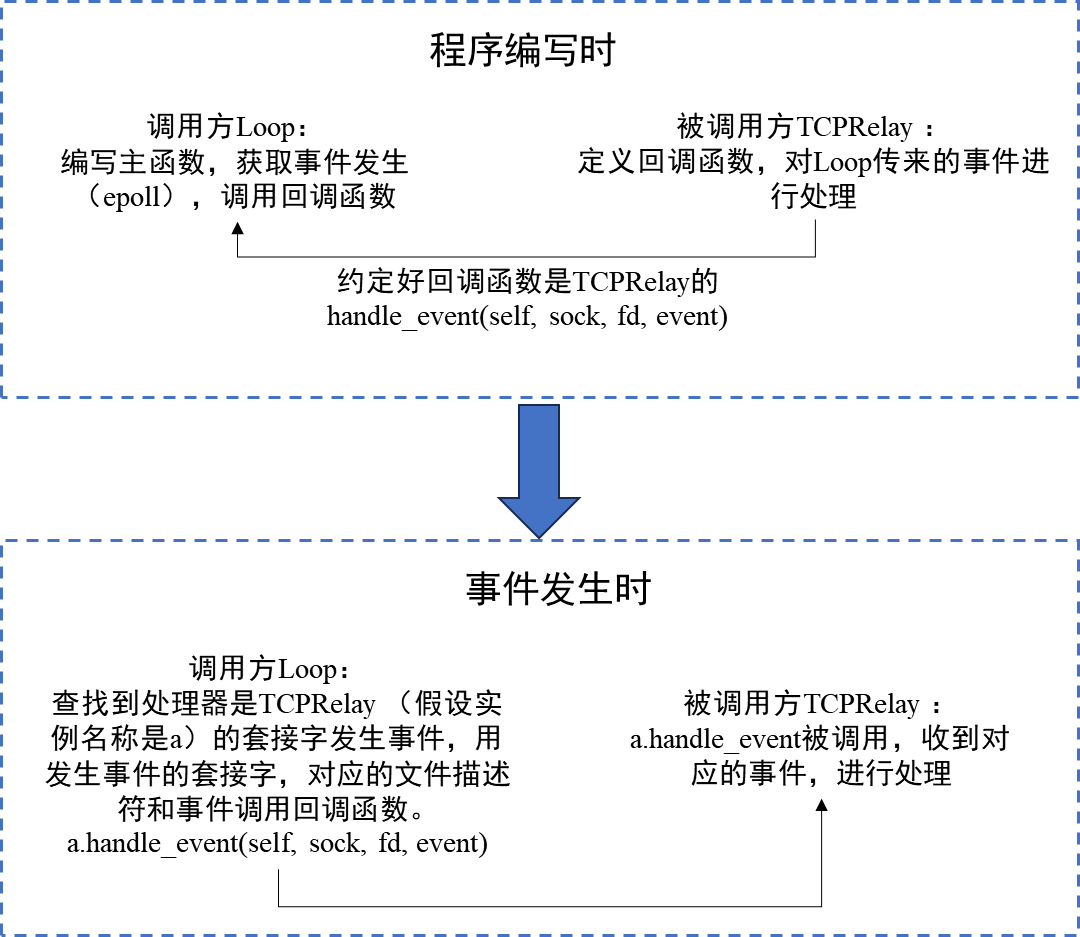
通过上述例子理解了基于事件的编程后,我们就可以分析shadowsocks在进行TCP连接代理时,总共在哪些地方使用了回调函数:除了上述提到的1.DNSResolver、TCPRelay套接字可读和TCPRelayHandler相关的套接字可读或可写(有数据来了或者有数据可以发送走),还有2.DNSResolver解析得到DNS记录后对TCPRelayHandler的回调(用于通知该解析结果对应的TCPRelayHandler和远端建立连接,并将连接后的套接字加入loop的监听事件)和3.DNSResolver、TCPRelay的超时回调,也就是二者每隔一段时间需要完成的动作,对于DNSResolver而言,是清除超时的DNS记录;对于TCPRelay而言,则是处理超时了的TCPRelayHandler连接(近端和远端很久都没有数据来到),这部分将放到超时处理部分详细记录,这里用来说明超时清理的实现也是通过回调函数完成的。
下面我们分析第二个使用回调函数的部分:DNSResolver收到DNS服务器返回的DNS查询记录后的行为,将相关的代码列出。
未删减的代码
class DNSResolver(object):
def handle_event(self, sock, fd, event):#针对不同情况写不同的事件处理
if sock != self._sock:
return
if event & eventloop.POLL_ERR:
logging.error('dns socket err')
self._loop.remove(self._sock)
self._sock.close()
# TODO when dns server is IPv6
self._sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM,
socket.SOL_UDP)
self._sock.setblocking(False)
self._loop.add(self._sock, eventloop.POLL_IN, self)#重新加
else:
data, addr = sock.recvfrom(1024)
if addr[0] not in self._servers:
logging.warn('received a packet other than our dns')
return
self._handle_data(data)#这是收到回复数据的处理
def _handle_data(self, data):
response = parse_response(data)
if response and response.hostname:
hostname = response.hostname
ip = None
for answer in response.answers:
if answer[1] in (QTYPE_A, QTYPE_AAAA) and \
answer[2] == QCLASS_IN:
ip = answer[0]#只会是地址
break
if not ip and self._hostname_status.get(hostname, STATUS_SECOND) \
== STATUS_FIRST:#ip为空并且是一阶段
self._hostname_status[hostname] = STATUS_SECOND
self._send_req(hostname, self._QTYPES[1])#ipv6请求不到 请求ipv4
else:
if ip:
self._cache[hostname] = ip#不计类型 可能是ipv4 不会是cname 添加到缓存 并
self._call_callback(hostname, ip)
elif self._hostname_status.get(hostname, None) \
== STATUS_SECOND:#无ip且二阶段
for question in response.questions:
if question[1] == self._QTYPES[1]:
self._call_callback(hostname, None)#第三分支 callback((hostname, None), Exception('unknown hostname %s' % hostname)) 无法解析
break
def _call_callback(self, hostname, ip, error=None):#收到回答后 通过域名和ip 再找出tcprelay的回调函数 并执行 然后将这个域名的回调删除了 并且删除一二阶段的状态字典
#在tcprelay中 def _handle_dns_resolved(self, result, error)
callbacks = self._hostname_to_cb.get(hostname, [])
for callback in callbacks:
if callback in self._cb_to_hostname:
del self._cb_to_hostname[callback]
if ip or error:
callback((hostname, ip), error)
else:
callback((hostname, None),
Exception('unknown hostname %s' % hostname))
if hostname in self._hostname_to_cb:
del self._hostname_to_cb[hostname]#避免重复查询
if hostname in self._hostname_status:
del self._hostname_status[hostname]
#多个连接查询一个hostname 返回时通过handle event调用 _handle_data 进而_call_callback回调域名相关回调函数
#对于一个域名 多次注册 _hostname_to_cb append的对象 逐个删除_cb_to_hostname的字典项并调用回调函数
#之后再删除_hostname_to_cb和_hostname_status中的hostname项 以说明完成查询
为便于理解,将其精简后:
class DNSResolver(object):
def handle_event(self, sock, fd, event):#针对不同情况写不同的事件处理
data, addr = sock.recvfrom(1024)
self._handle_data(data)#这是收到回复数据的处理
def _handle_data(self, data):
response = parse_response(data)
hostname = response.hostname
for answer in response.answers:
if answer[1] in (QTYPE_A, QTYPE_AAAA) and answer[2] == QCLASS_IN:
ip = answer[0]
break
self._cache[hostname] = ip
self._call_callback(hostname, ip)
def _call_callback(self, hostname, ip, error=None):
callbacks = self._hostname_to_cb.get(hostname, [])
for callback in callbacks:
callback((hostname, ip), error)
由此可见,DNSResolver的套接字在收到DNS回复数据报文后,执行了如下流程的操作:由loop的poll方法将事件分发给DNSResolver实例,DNSResolver实例调用handle_event处理事件,其中调用_handle_data解析收到的数据包,也就是DNS响应报文,从中取出ipv4或ipv6地址和对应的主机名(hostname)。然后针对元组(hostname,ip),调用_call_callback函数寻找查询了与这个hostname相关的回调函数,根据TCPRelayHandler中_handle_dns_resolved(self, result, error)的原型对回调函数进行调用,也就是最后一行的callback((hostname, ip), error)。
最后是第三个使用回调函数的部分,超时操作先不考虑,只学习由回调函数执行定期任务的代码:
class EventLoop(object):
def add_periodic(self, callback):
self._periodic_callbacks.append(callback)#列表添加一个callback
def run(self):
for callback in self._periodic_callbacks:#列表里加上callback 取出来逐个处理 注意原型里没有形参
callback()#对于dns而言 就是调用dnsresolver.handle_periodic() 也就是dnsresolver._cache.sweep() 属性的缓存的sweep方法 这里直接上就是清理队列 时间戳是再计算
class DNSResolver(object):
def add_to_loop(self, loop):
loop.add_periodic(self.handle_periodic)
def handle_periodic(self):
self._cache.sweep()
class TCPRelay(object):
def add_to_loop(self, loop):
self._eventloop.add_periodic(self.handle_periodic)
def handle_periodic(self):
self._sweep_timeout()
loop在执行run函数时,每次循环都会检查是否执行超时任务(省略),如果执行,就将self._periodic_callbacks列表中的回调函数取出并执行,也就是执行DNSResolver实例和TCPRelay实例各自的handle_periodic函数。二者均在添加到循环时,注册到loop的_periodic_callbacks列表中。这样做的目的是用来回收闲置资源,具体的回收就由DNSResolver类的_cache.sweep()方法和TCPRelay类的_sweep_timeout()方法实现,因此shadowsocks可以在路由器或者低配置VPS上占用较少的内存,稳定高效的运行。
以上,对shadowsocks在代理TCP连接时的基于事件编程方法和相关的回调函数的编写进行了较为详细的回顾,因为此前没有接触过这种编程模式,所以略显啰嗦。详细的整理一来是方便回顾,二来是希望在同样没有类似经验的朋友有兴趣学习shadowsocks程序源码时,可以帮助大家加深对事件驱动设计模式的理解,节约大家查阅相关资料的时间。
网络编程的I/O模型
这个部分我并没有看过相关的书籍,表述可能不准确,而且大多搬运看到的资料。因此如果有读者要浏览这部分内容,请多查阅其它资料避免产生知识性的错误。
手边有本《深入理解计算机系统》,其中第十二章“并发编程”,应该是相关内容,如果以后有阅读,希望可以完善补充这部分内容。
这一部分好像成碎碎念了,就当作是对已有的计网理解的整合和应用,和程序源码关系不大,如果有读者感兴趣看看,不感兴趣跳过就行。
主要参考资料:IO模型及select、poll、epoll和kqueue的区别_select/poll/epoll/kqueue-CSDN博客
litux.nl/mirror/unixnetworkprogramming/0131411551_ch06lev1sec2.html
4. Reactor反应器模式 - 简书 (jianshu.com)
阻塞IO(blocking IO)
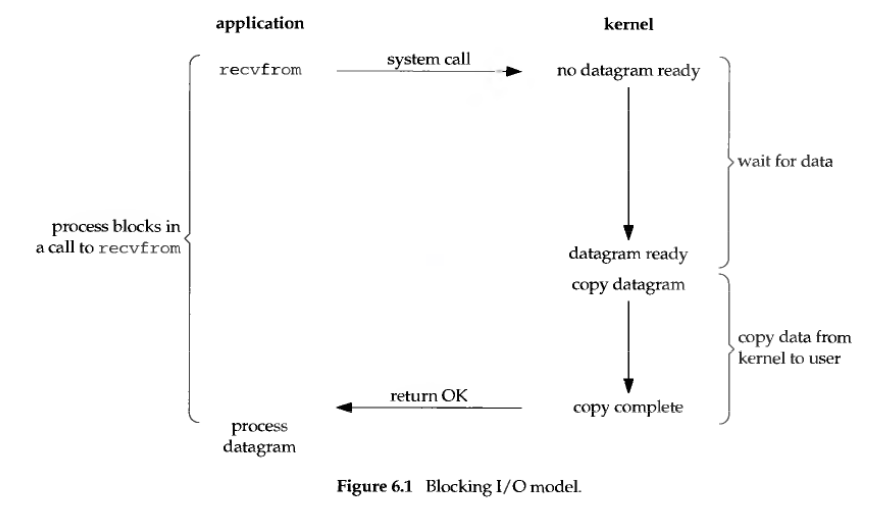
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程如上图所示。在《计算机网络:自顶向下方法(第七版)》第二章应用层2.7.2TCP套接字编程(P111)中,给出的示例就是这个形式,该书给出的简易TCP编程示例如下所示。
#TCPClient.py
from socket import *
serverName = '192.168.31.135'
serverPort = 12000
clientSocket = socket(AF_INET,SOCK_STREAM)
clientSocket.connect((serverName,serverPort))
sentence = input('Input lowercase sentence:')
clientSocket.send(sentence.encode())
modifiedSentence = clientSocket.recv(1024)
print('From Server: ',modifiedSentence.decode())
clientSocket.close()
#TCPServer.py
from socket import *
serverPort = 12000
serverSocket=socket(AF_INET,SOCK_STREAM)
serverSocket.bind(('',serverPort))
serverSocket.listen(1)
print('The server is ready to receive')
while True:
connectionSocket,addr = serverSocket.accept()
sentence = connectionSocket.recv(1024).decode()
capitalizedSentence = sentence.upper()
connectionSocket.send(capitalizedSentence.encode())
connectionSocket.close()
在尝试运行该教材程序时,会发现如果有两个client程序(假设A左上和B左下,不妨认为是A先运行,B后运行)向同一个server建立套接字连接,A在建立连接后一直未输入内容,而B优先输入内容时,会出现:会因为收不到接受了连接的A的数据,一直被socket.recv()阻塞的server,不会接受B的数据,导致B也被socket.recv()阻塞,不会运行到显示“Input lowercase sentence:”这一行;直到A输入一个内容收到回显后,B的连接才会被处理,程序继续运行。
从这个简单的回显(echo:把发过去的文字传回来重新显示的意思)程序来看,就能发现这种阻塞套接字的问题:为了接收数据,会将整个数据阻塞住,这不符合shadwosocks的设计要求。我们使用代理服务器时,要代理多个应用层程序的多个TCP连接,有着高并发性和随机性,不能够因为指定接收某个连接的数据而阻碍其他所有连接的数据,虽然采用多线程可以在各个线程采用阻塞IO套接字,但是那样系统开销过大,并不适合VPS等低性能机器,因此shadowsocks的程序实现中,并没有使用这种阻塞式的IO。
将本地抓包的图片专门放出,进行详细一点的分析说明,加深对TCP协议的理解,也可以帮助对TCP不熟悉的朋友初步理解TCP,这对于理解shadowsocks对数据流的处理是有所帮助的。在此推荐两本书,是林沛满先生的《Wireshark网络分析就这么简单》和《Wireshark网络分析的艺术》,作者从Wireshark解决实际问题的案例出发,专门分析了一些TCP的机制和一些出名的应用层协议,用语诙谐,作为入门书籍是非常合适的。抓包图片如下:
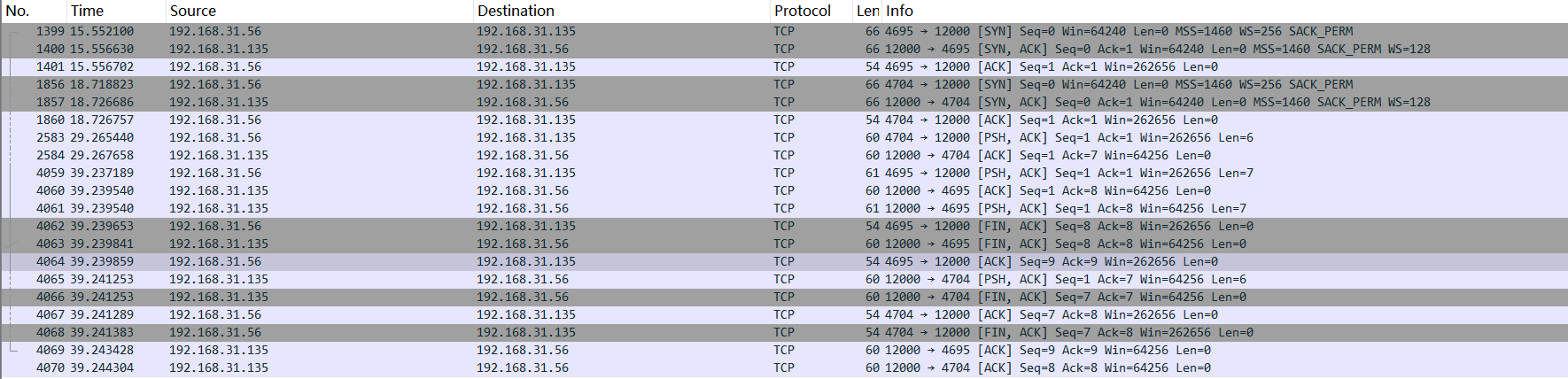
由此抓包可知,A client程序使用了192.168.31.56的4695端口,B client程序使用了192.168.31.56的4704端口,数据包按照client端的时间排序。A程序和B程序先后与server完成了TCP的三次握手(1399-1401)号包,(1856,1857和1860)号包。随后B程序于2583号数据包发送数据123123:
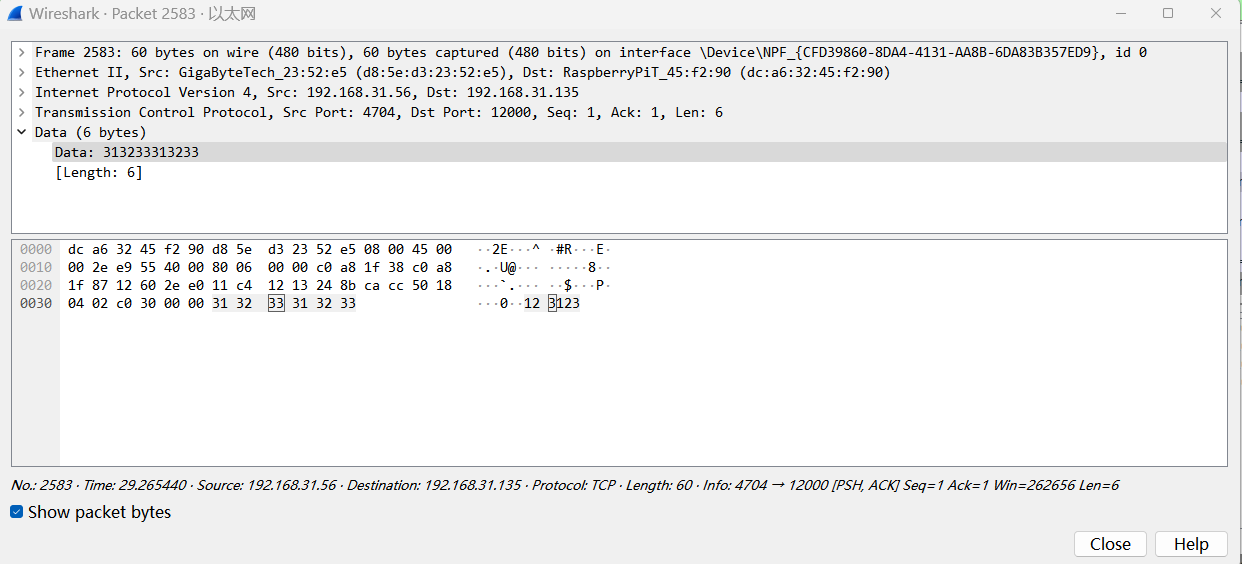
其中0x31 0x32 0x33是数字1 2 3的ASCII码,这个数据包立即被ACK(确认)了(2584号包),但是server程序应该是被循环里的sentence = connectionSocket.recv(1024).decode()函数阻塞的,这也说明了这个确认是由运输层机制确认的,而不是编写程序的应用层。随后A程序发送了数据包并得到了确认(4059和4060号包),server程序给A返回了回显的内容(4061号包),A回复确认并发起四次挥手,最后断开连接(4062,4063,4064和4069号包),注意4063号包不是对4062号包的ACK,4069才是(因为4043的ACK=8,而不是对FIN加了1的ACK)。这个地方是个人理解,没有求证,特此指出,希望不要误导他人。而B的数据在2583号包就已经发送,回显的内容却在4065号包才发送,这正是循环中先accept了先到达的A连接而后recv()阻塞的结果。
这个案例说的较为详细,也是为了说明我在阅读shadowsocks程序时一开始走的一点弯路:我们只需要着重于应用层设计的事情,对运输层的事情稍加关注,对于网络层及以下可以毫不关心。shadowsocks要做的事情是分析数据包从哪里来,要从哪里去,以及怎么去(加密和TCPHandler),与TCP的分段,IP的分片基本没有关系,这也是TCP/IP分层设计的好处。在未学习程序前,我曾想:shadowsocks local是如何将各个数据包原封不动的转发到server,再转发到destination。实际上数据包是发生了重新包装,client(如浏览器)给sslocal发的数据包不但和sslocal发给ssserver的数据包并不一一对应(有加密),甚至与ssserver发给destination的也并不一一对应,但是内部的数据流,也就是tcp承载的内容是一模一样的。这也就是流(stream)的概念。具体而言:数据流就是一长串二进制比特组成的有序排列,运输层TCP的责任是,保证这个流完完整整准准确确送到通信方,而具体哪一部分的bit流负责哪一个请求,这是由应用层设计划分的。
Shadowsocks的核心代理部分,只需要保证所有的bit都可以被准确按序转发,而不必在意哪个数据包承载了哪部分数据流。具体的应用层怎么处理数据流,我想到以前接触过的两个例子:应用层的HTTP协议和SMTP(Simple Mail Transfer Protocol)[^4]简单邮件传输协议。具体而言,一个HTTP请求可以由多个运输层报文段承载,一个报文段也可以携带多个HTTP。HTTP报文是通过两个CR+LF(回车换行符"\r\n")来确定报文头部结束,通过Content-Length来确定实体(Body)部分的长度,也就是由应用层来将bit流划分成合适的部分;SMTP在通过telnet实验时,也是用CR+LF来表示命令的结束。这均一定程度说明了应用层和运输层之间的关系。类似的思想也类似于字符编码,对字节串b'\xe6\x97\xa5'而言,使用 UTF-8 解码得到一个日文字符 "日",使用Latin-1 解码,在 Latin-1 中分别对应字节 b'\xe6' 和 b'\x97',分别被解释为字符 "æ" 和 "—"(来源于chatGPT),就好比同一个数据流传到不同的应用层可能得到不同的请求(在不出现异常的理想情况下,仅仅用来类比)。Shadowsocks在处理Socks5握手和解析DNS报文时,也编写了按照RFC1928[^5]和RFC1034[^6]及1035[^7]处理收到字节流的函数,也是一定程度体现了这种应用层设计的思想。
插句题外话,在准备素材时,增强了对套接字编程的进一步理解,特别是socket的listen()方法和accpet()方法,来源为[^3]
- 以前对TCP三次握手和socket API之间的对应关系是这样理解的。
- 服务器调用listen进行监听
- 客户端调用connect来发送syn报文
- 服务器调用accept来回复[syn,ack]
- 客户端协议栈进行ack确认
- 最近看完了TCP/IP详解后,发现自己的理解是错的,真正的对应关系是这样的。
- 服务器调用listen进行监听
- 客户端调用connect来发送syn报文
- 服务器协议栈负责三次握手的交互过程。连接建立后,往listen队列中添加一个成功的连接,直到队列的最大长度。
- 服务器调用accept从listen队列中取出一条成功的tcp连接,listen队列中的连接个数就少一个
注:listen的函数形式int listen(int sockfd, int backlog); backlog代表listen队列的长度。
进而对socket.listen()方法也加深了理解,我们尝试运行四个client对这个阻塞IOserver发起请求:
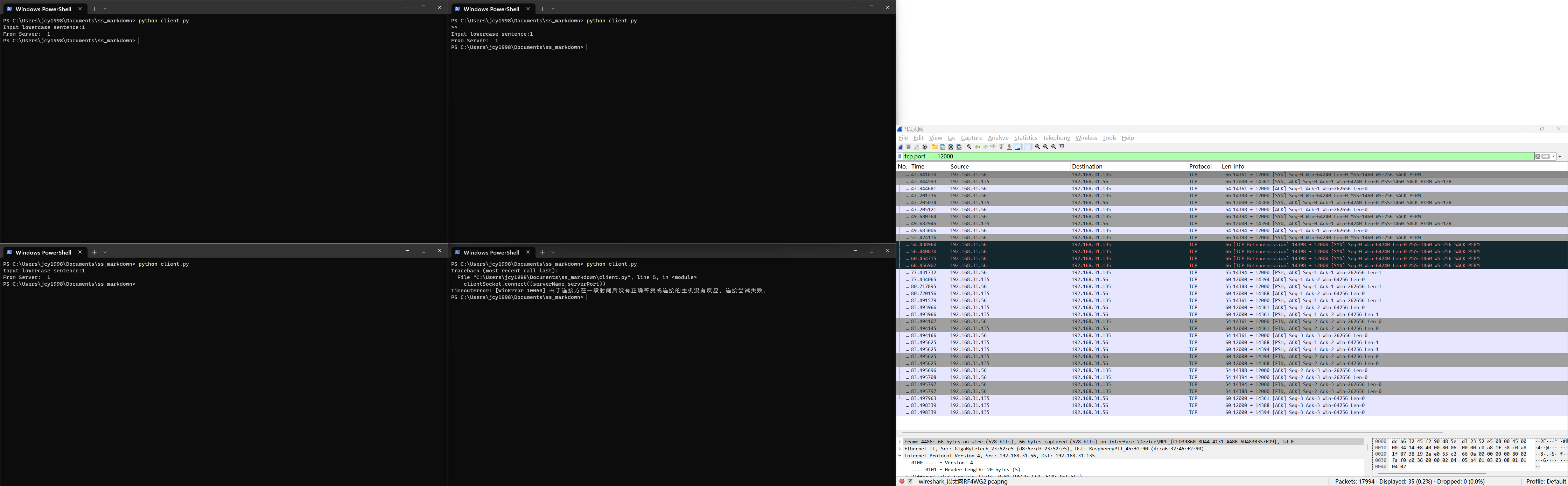
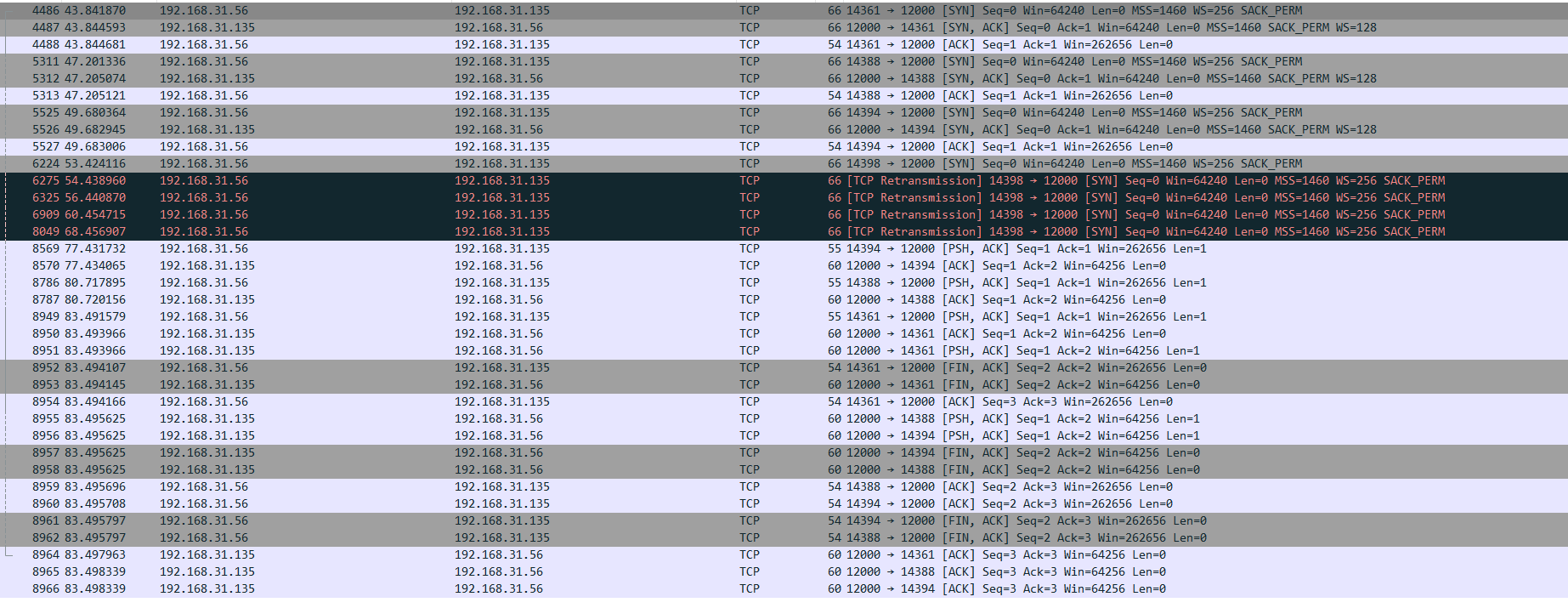
其中四个client是按照左下,左上,右上,右下的顺序启动,由wireshark可知端口分别为:14361,14388,14394和14398,其中出现TCP重传(TCP Retransmission)的四个包均由client设备的14398端口发出,也就是最后启动的client程序。
其中linux上tcpdump抓包结果如下
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
12:29:56.952627 IP DESKTOP-29ERA2T.14361 > dca63245f290.12000: Flags [S], seq 1405249034, win 64240, options [mss 1460,nop,wscale 8,nop,nop,sackOK], length 0
12:29:56.952796 IP dca63245f290.12000 > DESKTOP-29ERA2T.14361: Flags [S.], seq 838946265, ack 1405249035, win 64240, options [mss 1460,nop,nop,sackOK,nop,wscale 7], length 0
12:29:56.955304 IP DESKTOP-29ERA2T.14361 > dca63245f290.12000: Flags [.], ack 1, win 1026, length 0
12:30:00.313133 IP DESKTOP-29ERA2T.14388 > dca63245f290.12000: Flags [S], seq 2308462481, win 64240, options [mss 1460,nop,wscale 8,nop,nop,sackOK], length 0
12:30:00.313276 IP dca63245f290.12000 > DESKTOP-29ERA2T.14388: Flags [S.], seq 290689984, ack 2308462482, win 64240, options [mss 1460,nop,nop,sackOK,nop,wscale 7], length 0
12:30:00.316937 IP DESKTOP-29ERA2T.14388 > dca63245f290.12000: Flags [.], ack 1, win 1026, length 0
12:30:02.791056 IP DESKTOP-29ERA2T.14394 > dca63245f290.12000: Flags [S], seq 2314767347, win 64240, options [mss 1460,nop,wscale 8,nop,nop,sackOK], length 0
12:30:02.791258 IP dca63245f290.12000 > DESKTOP-29ERA2T.14394: Flags [S.], seq 3406901438, ack 2314767348, win 64240, options [mss 1460,nop,nop,sackOK,nop,wscale 7], length 0
12:30:02.793948 IP DESKTOP-29ERA2T.14394 > dca63245f290.12000: Flags [.], ack 1, win 1026, length 0
12:30:06.535721 IP DESKTOP-29ERA2T.14398 > dca63245f290.12000: Flags [S], seq 3267839523, win 64240, options [mss 1460,nop,wscale 8,nop,nop,sackOK], length 0
12:30:07.550803 IP DESKTOP-29ERA2T.14398 > dca63245f290.12000: Flags [S], seq 3267839523, win 64240, options [mss 1460,nop,wscale 8,nop,nop,sackOK], length 0
12:30:09.553428 IP DESKTOP-29ERA2T.14398 > dca63245f290.12000: Flags [S], seq 3267839523, win 64240, options [mss 1460,nop,wscale 8,nop,nop,sackOK], length 0
12:30:13.566158 IP DESKTOP-29ERA2T.14398 > dca63245f290.12000: Flags [S], seq 3267839523, win 64240, options [mss 1460,nop,wscale 8,nop,nop,sackOK], length 0
12:30:21.567804 IP DESKTOP-29ERA2T.14398 > dca63245f290.12000: Flags [S], seq 3267839523, win 64240, options [mss 1460,nop,wscale 8,nop,nop,sackOK], length 0
12:30:30.542433 IP DESKTOP-29ERA2T.14394 > dca63245f290.12000: Flags [P.], seq 1:2, ack 1, win 1026, length 1
12:30:30.542498 IP dca63245f290.12000 > DESKTOP-29ERA2T.14394: Flags [.], ack 2, win 502, length 0
12:30:33.828484 IP DESKTOP-29ERA2T.14388 > dca63245f290.12000: Flags [P.], seq 1:2, ack 1, win 1026, length 1
12:30:33.828602 IP dca63245f290.12000 > DESKTOP-29ERA2T.14388: Flags [.], ack 2, win 502, length 0
12:30:36.602151 IP DESKTOP-29ERA2T.14361 > dca63245f290.12000: Flags [P.], seq 1:2, ack 1, win 1026, length 1
12:30:36.602245 IP dca63245f290.12000 > DESKTOP-29ERA2T.14361: Flags [.], ack 2, win 502, length 0
12:30:36.602355 IP dca63245f290.12000 > DESKTOP-29ERA2T.14361: Flags [P.], seq 1:2, ack 2, win 502, length 1
12:30:36.602425 IP dca63245f290.12000 > DESKTOP-29ERA2T.14361: Flags [F.], seq 2, ack 2, win 502, length 0
12:30:36.602727 IP dca63245f290.12000 > DESKTOP-29ERA2T.14388: Flags [P.], seq 1:2, ack 2, win 502, length 1
12:30:36.602771 IP dca63245f290.12000 > DESKTOP-29ERA2T.14388: Flags [F.], seq 2, ack 2, win 502, length 0
12:30:36.602934 IP dca63245f290.12000 > DESKTOP-29ERA2T.14394: Flags [P.], seq 1:2, ack 2, win 502, length 1
12:30:36.602974 IP dca63245f290.12000 > DESKTOP-29ERA2T.14394: Flags [F.], seq 2, ack 2, win 502, length 0
12:30:36.605283 IP DESKTOP-29ERA2T.14361 > dca63245f290.12000: Flags [F.], seq 2, ack 2, win 1026, length 0
12:30:36.605293 IP DESKTOP-29ERA2T.14361 > dca63245f290.12000: Flags [.], ack 3, win 1026, length 0
12:30:36.605343 IP dca63245f290.12000 > DESKTOP-29ERA2T.14361: Flags [.], ack 3, win 502, length 0
12:30:36.606306 IP DESKTOP-29ERA2T.14388 > dca63245f290.12000: Flags [.], ack 3, win 1026, length 0
12:30:36.606314 IP DESKTOP-29ERA2T.14394 > dca63245f290.12000: Flags [.], ack 3, win 1026, length 0
12:30:36.606375 IP DESKTOP-29ERA2T.14394 > dca63245f290.12000: Flags [F.], seq 2, ack 3, win 1026, length 0
12:30:36.606379 IP DESKTOP-29ERA2T.14388 > dca63245f290.12000: Flags [F.], seq 2, ack 3, win 1026, length 0
12:30:36.606426 IP dca63245f290.12000 > DESKTOP-29ERA2T.14394: Flags [.], ack 3, win 502, length 0
12:30:36.606453 IP dca63245f290.12000 > DESKTOP-29ERA2T.14388: Flags [.], ack 3, win 502, length 0
其中空行隔开的就是第四个连接,可见server所在主机没有接收这个SYN的TCP连接请求,也就是收到了socket.listen()中参数的影响。由12:30:36.602425的包的ACK编码和FIN标记,也可以印证之前关于之前4069号包的讨论,不重复说明。其他数据流向也与两个client时结果一致,不重复说明。
我们尝试将listen方法的参数置为0,得到如下结果:
发现只有两个Client完成了TCP的三次握手,也就是2827和2837端口,而2843和2838端口的TCP连接均没有建立。除去server程序循环中accept的套接字,说明listen队列中只能存放一个待接受的连接。也就是一个长度为1,最大编号为0的队列。实际如下图所示,图片来源关于网络编程socket的listen底层的一点理解_listen底层有哪些队列-CSDN博客,其中也包含一些分析,有兴趣的朋友请自行点击分析。
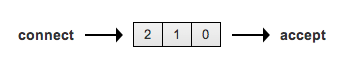
对于阻塞IO,就想起这么多,可能有点跑题了,不过也是放在自己的站点上,应该也没有关系吧!总而言之,对阻塞IO的学习,让我们知道Shadowsocks不适用于这种设计方法,并且初步理解了应用层和运输层的关系,对流的概念有一个粗糙的理解,这为后面数据传输状态机和加密解密的理解做了一定的准备工作。
非阻塞IO (non-blocking IO)
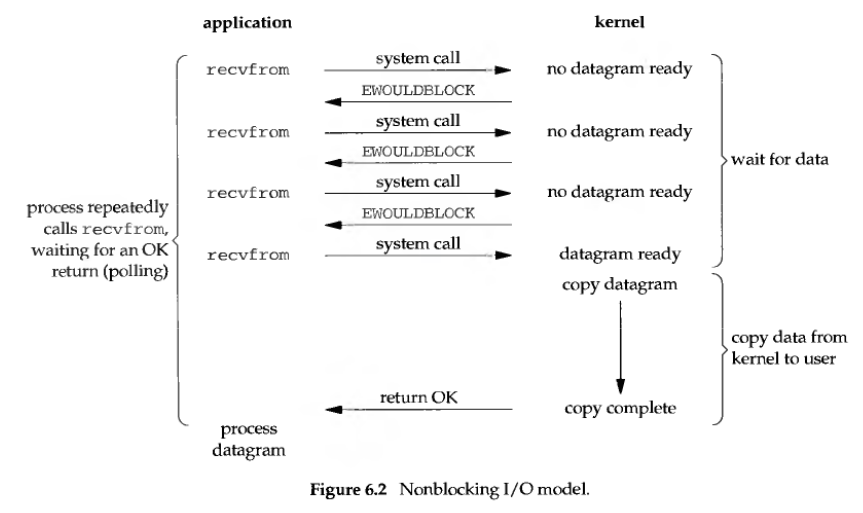
当套接字设置成非阻塞模式时,如果无法立即完成请求,不会被阻塞,而是返回错误EWOULDBLOCK。但是直接使用这种套接字模式设计程序需要不停轮询(polling),这样会消耗大量的CPU时间。在python网络编程中,设置套接字为非阻塞模式,是通过socket.setblocking(False)方法实现的。
Shadowsocks没有直接按照recv()->轮询->recv()->轮询的方式编程,但是将套接字都设置成了非阻塞模式,这样在读写时,不会因为暂时无法写入或读取而将进程阻塞。通过非阻塞IO的设置,读取和写入从一直等待直到成功变成了尝试一次,如果未完成则进一步处理,可以保证程序的高效稳定的运行。
在Shadowsocks中,基于非阻塞IO编写程序的一个典型例子就是tcprelay.py中TCPRelayHandler类的_write_to_sock方法,代码如下:
class TCPRelayHandler(object):
def __init__(self, server, fd_to_handlers, loop, local_sock, config, dns_resolver, is_local):
local_sock.setblocking(False)
def _create_remote_socket(self, ip, port):
addrs = socket.getaddrinfo(ip, port, 0, socket.SOCK_STREAM,socket.SOL_TCP)
af, socktype, proto, canonname, sa = addrs[0]
remote_sock = socket.socket(af, socktype, proto)
self._remote_sock = remote_sock
remote_sock.setblocking(False)
return remote_sock
def _write_to_sock(self, data, sock):
# write data to sock
# if only some of the data are written, put remaining in the buffer
# and update the stream to wait for writing
if not data or not sock:
return False
uncomplete = False
try:
l = len(data)
s = sock.send(data)#它返回一个整数值,表示实际发送的字节数
if s
一个TCPHandler在整个生存周期只负责两个套接字,一个近端(对于local程序就是与socks5 client的套接字,对server程序就是来自local程序的套接字),一个远端(对于local程序就是与server的套接字,对server程序就是到真实请求目的地destination的套接字)。二者均被设置为非阻塞模式。这样在_write_to_sock方法中可以立即获得发送成功的长度s = sock.send(data),如果发送失败或者部分发送并不会在这里阻塞住进程,而是通过 uncomplete标记进一步处理,将未写完的数据存到本地缓存中(_data_to_write_to_remote或_data_to_write_to_local列表中)。这样当上次未写完的套接字可写时(通过loop的poll()方法获取事件进行回调),就可以将_data_to_write_to_local/remote中的数据作为_write_to_sock的data参数继续发送,如果还没有发送完全,则再次重复这个流程。这样就利用了非阻塞IO的特性,实现了高效的数据传输。
IO多路复用(IO multiplexing)
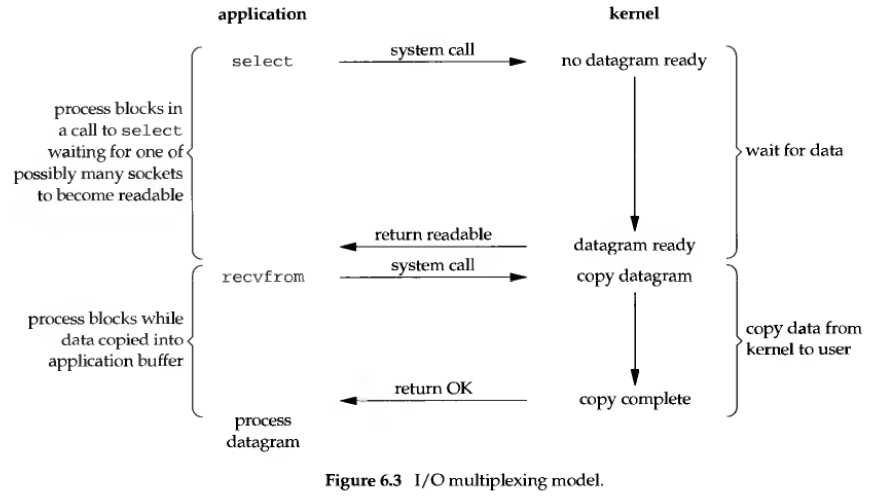
首先引入一段chatgpt多路复用的描述:
IO多路复用是一种在单个线程中管理多个IO操作的机制。它允许一个进程可以同时监听多个文件描述符(如套接字、文件、管道等)的IO事件,从而在这些IO事件发生时进行处理,而不需要为每个IO操作创建新的线程或进程。常见的IO多路复用技术包括select、poll和epoll。这种方法可以提高系统的性能和效率,因为它避免了创建大量线程或进程带来的资源开销和管理负担。
IO多路复用仍是一种同步IO编程方法,但是与之前提到的阻塞IO不同,IO多路复用可以在一次阻塞中获得多个文件描述符(在这里等价于套接字)的事件,这样就可以通过主循环(loop循环)阻塞一次,获得当前监听的所有事件,再逐事件处理,处理完这一轮的事件,再循环获得下一轮的事件。从而实现只用一个进程来完成多个数据流的转发,特别适用于VPS等低性能机器长期稳定的运行。
Shadowsocks在选取IO多路复用相关库时,优先使用epoll,其次是kqueue,最后是select,但是将三者封装了与epoll一样的接口,代码如下:
```
class KqueueLoop(object):#提供类似于epoll的接口 一样的输入 一样的输出 即一样的原型
MAX_EVENTS = 1024
def __init__(self):
self._kqueue = select.kqueue()
self._fds = {}
def _control(self, fd, mode, flags):
events = []
if mode & POLL_IN:
events.append(select.kevent(fd, select.KQ_FILTER_READ, flags))
if mode & POLL_OUT:
events.append(select.kevent(fd, select.KQ_FILTER_WRITE, flags))
for e in events:
self._kqueue.control([e], 0)
def poll(self, timeout):
if timeout < 0:
timeout = None # kqueue behaviour
events = self._kqueue.control(None, KqueueLoop.MAX_EVENTS, timeout)
results = defaultdict(lambda: POLL_NULL)
for e in events:
fd = e.ident
if e.filter == select.KQ_FILTER_READ:
results[fd] |= POLL_IN
elif e.filter == select.KQ_FILTER_WRITE:
results[fd] |= POLL_OUT
return results.items()
def register(self, fd, mode): #对应于Eventloop类的self._impl.register(fd, mode)
self._fds[fd] = mode
self._control(fd, mode, select.KQ_EV_ADD)
def unregister(self, fd):
self._control(fd, self._fds[fd], select.KQ_EV_DELETE)
del self._fds[fd]
def modify(self, fd, mode):
self.unregister(fd)
self.register(fd, mode)
def close(self):
self._kqueue.close()
#晚点看
class SelectLoop(object):
def __init__(self):
self._r_list = set()
self._w_list = set()
self._x_list = set()
def poll(self, timeout):
r, w, x = select.select(self._r_list, self._w_list, self._x_list,
timeout)
results = defaultdict(lambda: POLL_NULL)
for p in [(r, POLL_IN), (w, POLL_OUT), (x, POLL_ERR)]:
for fd in p[0]:
results[fd] |= p[1]
return results.items()
def register(self, fd, mode):
if mode & POLL_IN:
self._r_list.add(fd)
if mode & POLL_OUT:
self._w_list.add(fd)
if mode & POLL_ERR:
self._x_list.add(fd)
def unregister(self, fd):
if fd in self._r_list:
self._r_list.remove(fd)
if fd in self._w_list:
self._w_list.remove(fd)
if fd in self._x_list:
self._x_list.remove(fd)
def modify(self, fd, mode):
self.unregister(fd)
self.register(fd, mode)
def close(self):
pass
```
这样就能实现程序编写的一致性。看别人的分析[^8],epoll也是优于select的,优先使用epoll也是有道理的,原因如下:
epoll的最大好处是不会随着FD的数目增长而降低效率,在select中采用轮询处理,其中的数据结构类似一个数组的数据结构,而epoll是维护一个队列,直接看队列是不是空就可以了。epoll只会对"活跃"的socket进行操作---这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有"活跃"的socket才会主动的去调用 callback函数(把这个句柄加入队列),其他idle状态句柄则不会,在这点上,epoll实现了一个"伪"AIO。但是如果绝大部分的I/O都是“活跃的”,每个I/O端口使用率很高的话,epoll效率不一定比select高(可能是要维护队列复杂)。
我对这方面了解很少,可以说现在仅仅有点概念,现在就知道优先用的epoll效果更好,以及基本的实现原理,具体学习以后再说。
通过IO多路复用机制,Shadowsocks既避免了阻塞IO造成程序的阻塞和低效,又避免了非阻塞IO直接编程的不停轮询,可以运行一次poll()函数就得到一批当前要处理的事件。
IO多路复用机制下的设计模式:反应器(Reactor)模型
反应器模型是上文提到的基于事件驱动的编程模型之一,实际上在前文分析TCPRelay、DNSResolver、TCPRelayHandler类的handle_event()函数时,就已经涉及了具体的程序实现。但是在学习过程中,阅读资料对这种设计模式有了更进一步的了解。在此写一写学习心得。首先选取wiki上的描述[^ 9]:
The reactor software design pattern is an event handling strategy that can respond to many potential service requests concurrently. The pattern's key component is an event loop, running in a single thread or process, which demultiplexes incoming requests and dispatches them to the correct request handler.
By relying on event-based mechanisms rather than blocking I/O or multi-threading, a reactor can handle many concurrent I/O bound requests with minimal delay.A reactor also allows for easily modifying or expanding specific request handler routines, though the pattern does have some drawbacks and limitations.
A reactive application consists of several moving parts and will rely on some support mechanisms:
Handle
An identifier and interface to a specific request, with IO and data. This will often take the form of a socket, file descriptor, or similar mechanism, which should be provided by most modern operating systems.
Demultiplexer
An event notifier that can efficiently monitor the status of a handle, then notify other subsystems of a relevant status change (typically an IO handle becoming "ready to read"). Traditionally this role was filled by the select() system call, but more contemporary examples include epoll, kqueue, and IOCP.
Dispatcher
The actual event loop of the reactive application, this component maintains the registry of valid event handlers, then invokes the appropriate handler when an event is raised.
Event Handler
Also known as a request handler, this is the specific logic for processing one type of service request. The reactor pattern suggests registering these dynamically with the dispatcher as callbacks for greater flexibility. By default, a reactor does not use multi-threading but invokes a request handler within the same thread as the dispatcher.
Event Handler Interface
An abstract interface class, representing the general properties and methods of an event handler. Each specific handler must implement this interface while the dispatcher will operate on the event handlers through this interface.
翻译过来是这样的:
这个反应器软件设计模式是一种事件处理策略,能够同时响应许多潜在的服务请求。该模式的关键组件是一个事件循环,在单个线程或进程中运行,它对传入的请求进行多路复用,然后将它们分派给正确的请求处理器。
通过依赖基于事件的机制而不是阻塞I/O或多线程,反应器可以以最小的延迟处理许多并发的I/O绑定请求。反应器还允许轻松修改或扩展特定的请求处理程序例程,尽管该模式确实有一些缺点和限制。
反应器应用程序由多个活动部件组成,并依赖于一些支持机制:
Handle(句柄)
一个特定请求的标识符和接口,带有 I/O 和数据。通常采用套接字、文件描述符或类似机制的形式,这些机制应该由大多数现代操作系统提供。
Demultiplexer(多路复用器)
一种事件通知器,能够高效地监视句柄的状态,然后通知其他子系统有关相关状态变化的情况(通常是 IO 句柄变为“可读”的情况)。传统上,这个角色是由 select() 系统调用来实现的,但更现代的例子包括 epoll、kqueue 和 IOCP。
Dispatcher(调度器)
响应式应用程序的实际事件循环,该组件维护有效事件处理程序的注册表,当事件发生时调用相应的处理程序。
Event Handler(事件处理程序)
也称为请求处理程序,这是处理一种类型的服务请求的具体逻辑。反应器模式建议动态地将这些注册为调度器的回调函数,以获得更大的灵活性。默认情况下,反应器不使用多线程,而是在与调度器相同的线程中调用请求处理程序。
Event Handler Interface(事件处理程序接口)
一个抽象接口类,表示事件处理程序的一般属性和方法。每个具体的处理程序必须实现这个接口,而调度器将通过这个接口操作事件处理程序。
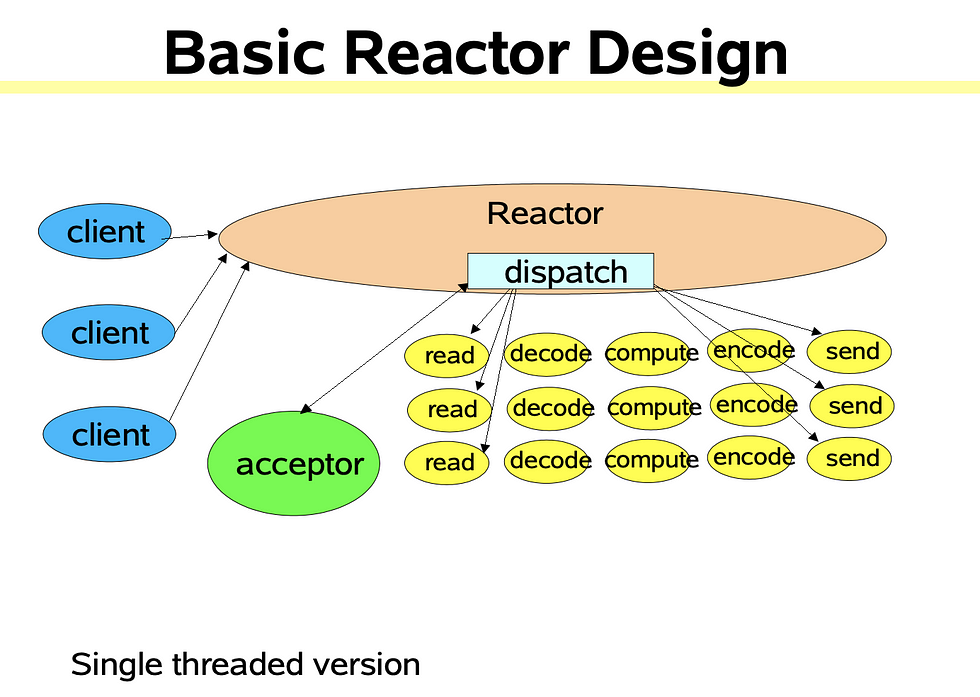
按照Doug Lea著名的文章《Scalable IO in Java》,来源^10,反应器模式由Reactor反应器线程、Handlers处理器两大角色组成:
- Reactor反应器线程的职责:负责响应IO事件,并且分发到Handlers处理器。
- Handlers处理器的职责:非阻塞的执行业务处理逻辑。
下图可以很好的说明这种关系,Shadowsocks仅使用单线程,故下列内容都在单线程范围内。[^10]
或者换一个更具体化符合Shadowsocks的图(这个是local程序,server程序就不是socks5 client了),这是我的个人理解可能不准确,只考虑一部分的关系:TCPRelay相关,即接受连接请求和TCPHandler负责的处理数据相关:
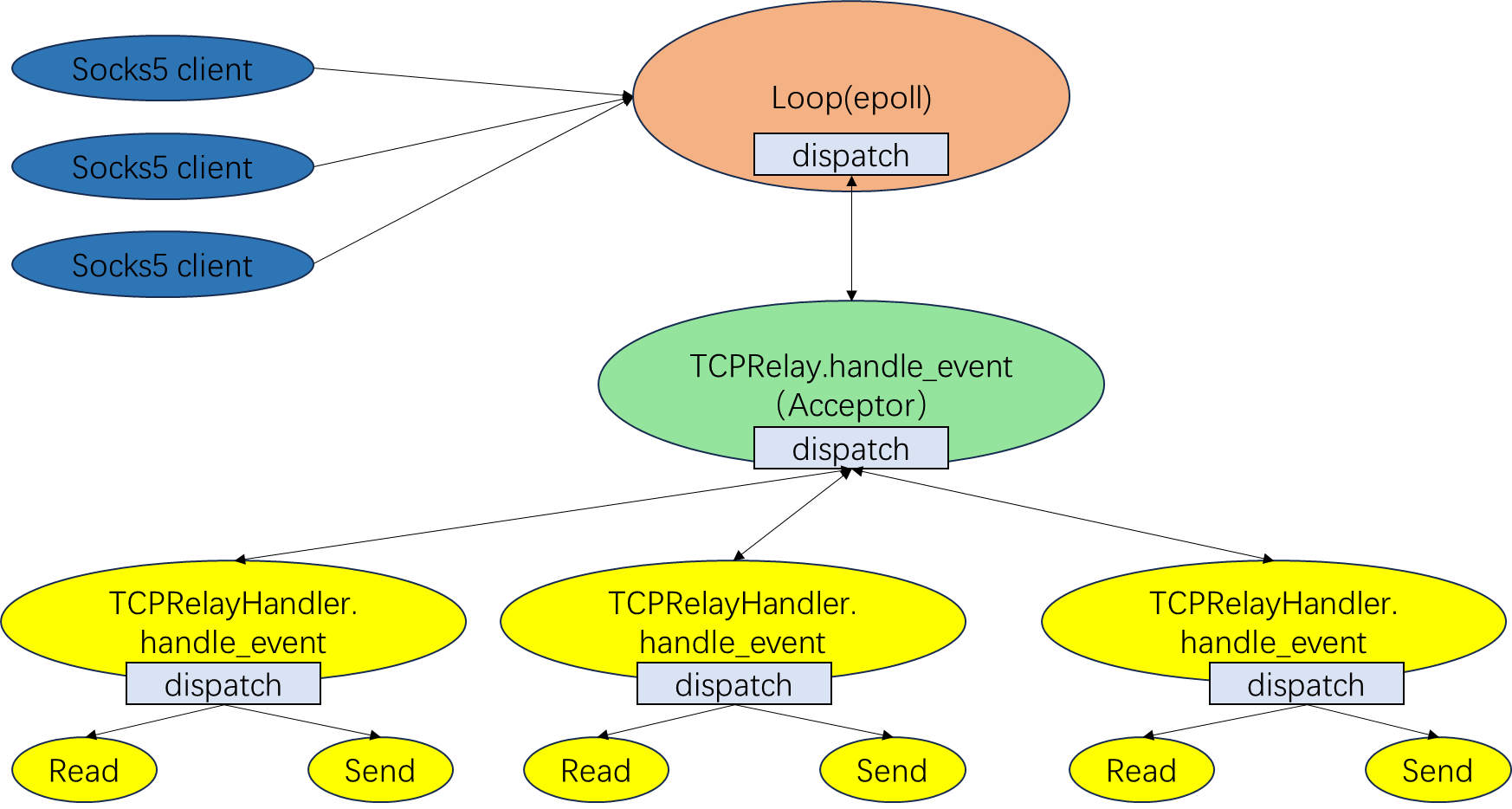
其中,单向箭头仅仅代表事务处理流程,双向箭头还要代表进行处理器的注册,以保证事务可以正常分发。具体的事件分发和处理流程上一部分已经比较详细的分析了,这里仅强调Shadowsocks使用了反应器的设计模式,以及各个类和函数在反应器模式下的对应关系。
而反应器模型和之前提到的非阻塞IO与IO多路复用的关系如下:反应器模型通常结合IO多路复用技术(如select、epoll)来实现。IO多路复用允许反应器同时监视多个IO事件,当这些事件就绪时,反应器负责将其分发给相应的处理程序进行处理。非阻塞IO则允许在IO操作中立即返回,而不阻塞进程,这样反应器模型可以及时处理各种事件,包括数据未写入完成、写入失败等情况,而不至于阻塞整个系统,从而实现Handlers处理器的职责。这种组合能够实现高效的IO处理和事件分发,提高系统的响应能力和并发处理能力。对于Shadowsocks,反应器就是loop的run函数,处理器就是各个handle_event函数,通过handler = self._fdmap.get(fd, None)和handler.handle_event(sock, fd, event)完成事件的分发(TCPRelay到TCPRelayHandler的分发类似)。
TCP代理是如何实现的?
在学习完了Shadowsocks的程序设计模型后,我们将走进更为实际的问题:一条TCP流是如何被代理的?这个问题可以被分解成两个问题:一是最终的目标服务器地址如何确定,也就是如何实现DNS解析?这是去哪里的问题。二是如何完成数据流的转发?这是怎么去的问题。而加密方法的问题,在这里显得并不重要,只需要知道:有一个接口,可以给所有的数据流实现逐比特的加密和解密,只需要在数据发送/接受时,调用一个encrypt或者decrypt即可完成,具体的内容将会在之后的一节中进行分析。本节的重点是TCP流的代理如何实现,这也是我在阅读代码时学习到最多的东西,接下来将之前分析的两个问题学习体会逐一进行分析,以供之后回顾。
DNS远程解析如何实现?
当与目标服务器建立连接时,我们通常从一个域名出发,这需要进行DNS解析,得到最终的服务器地址。为了给不太了解的朋友说明,举个例子DNS:google.com->172.217.12.142。这样做的好处是方便记忆,同时也有利于服务器所有者的维护和拓展。在进行TCP代理时,解析DNS的位置是一个值得探讨的问题。在很多情况下,DNS解析应当在代理服务器(server)完成,因为DNS应答服务器通常返回离请求端最近的可用IP地址,从而提升网络服务性能。在TCP代理中,最终与目标服务器建立连接的是代理服务器(server),因此在服务器端完成DNS解析有助于提高用户体验。此外,这也能够应对本地DNS服务器失效或提供不准确信息的情况(比如自己搭建的DNS服务器挂了)。这种方法有助于优化性能,确保连接尽可能快速和可靠。
Shadowsocks提供了DNS远程解析的功能,实现如下:通过socks5协议connect请求的相关约定,获取目标站点的地址(ip地址或域名),提交到ssserver的DNSResolver实例处理。在DNSResolver实例中,先检查是否是ip地址、再检查域名(hostname)是否在主机的hosts文件(读取配置时获得)中、是否在本地DNS缓存中,如果是则直接发起回调,说明DNS已经解析完成,TCPRelayHandler进入下一阶段,可以直接通过返回ip地址与远端建立连接;如果本地缓存没有该域名的DNS解析记录,就向公共DNS发起查询请求,等待回复A记录(域名对应的ipv4地址)或AAAA记录(域名对应的ipv6地址),在解析报文后,调用回调函数,通知对应的TCPRelayHandler查询完成,使用查询到的ip地址与远端建立连接。
为了方便理解代码,我们从每个连接,也就是TCPRelayHandler对DNS的调用看起:
class TCPRelayHandler(object):
def _handle_stage_addr(self, data):
if self._is_local:
self._dns_resolver.resolve(self._chosen_server[0],self._handle_dns_resolved)#也对ssserver的ip地址进行查询
else:
self._dns_resolver.resolve(remote_addr,self._handle_dns_resolved)
但实际一条TCP连接的代理中出现了两次DNS解析:sslocal程序和ssserver程序都需要进行DNS解析:条件判断语句可以发现local和server解析的地址不同,local程序解析的是ssserver的ip地址(这是上一段没有提到的),而ssserver解析的是目标服务器的ip地址,如github站点的ip地址。画了下面一个图进行说明,DNS解析的都是各自的remote端的ip地址,这实现了编程时代码的高度复用,保持sslocal程序和ssserver程序的TCP中继连接函数(TCPRelayHandler类)的一致性:二者均接受框左侧local socket的连接,自己主动寻址并连接右侧的remote socket。这样还可以让local配置文件中的”服务器地址“填入域名形式,通过在本地完成DNS解析获取ip地址,进而连接到服务器。

进而将关注点转移到DNSResolver类,特别是resolve方法:
class DNSResolver(object):
def resolve(self, hostname, callback):
if type(hostname) != bytes:
hostname = hostname.encode('utf8')#转为bytes
if not hostname:
callback(None, Exception('empty hostname'))#原型是(self, result, error)
elif common.is_ip(hostname):
callback((hostname, hostname), None)#是ip直接回调
elif hostname in self._hosts:
logging.debug('hit hosts: %s', hostname)
ip = self._hosts[hostname]
callback((hostname, ip), None)
elif hostname in self._cache:
logging.debug('hit cache: %s', hostname)
ip = self._cache[hostname]
callback((hostname, ip), None)#从缓存调出
else:
if not is_valid_hostname(hostname):
callback(None, Exception('invalid hostname: %s' % hostname))#判断是不是有校域名
return
arr = self._hostname_to_cb.get(hostname, None)#检查这个hostname有没有回调函数 在dns类的对象中
if not arr:
self._hostname_status[hostname] = STATUS_FIRST#注册阶段1
self._send_req(hostname, self._QTYPES[0])
self._hostname_to_cb[hostname] = [callback]#注册回调函数 针对域名 注册回调函数
self._cb_to_hostname[callback] = hostname
else:
arr.append(callback)#添加回调 时间太长重新发了 已经有记录了 这里应该再次发送 还按第一次发
# TODO send again only if waited too long
self._send_req(hostname, self._QTYPES[0])
DNSResolver的resolve方法,根据原型可知,输入第一个参数是要查询的域名,第二个参数是这个域名相关的回调函数,也就是这个域名解析结束应该调用的函数。DNS实际的查询实际是只有最后else分支的这三行:self._send_req(hostname, self._QTYPES[0])、self._hostname_to_cb[hostname] = [callback]和self._cb_to_hostname[callback] = hostname。其中第一行是用来发送请求,self._QTYPES[0]是用来指定查询ipv4还是ipv6地址;第二行是用来注册主机名相关的回调函数,可以理解成是某个TCPRelayHandler实例相关的连接,这里需要注意的是,一个主机名可能对应着多个回调函数,也就说有多个TCPRelayHandler可能请求同一个主机名,所以这里用的是列表[callback],从而可以使用append方法新增其他的回调函数,方便在域名请求成功时,通知所有请求该域名的TCPRelayHandler;第三行是用来记录回调函数相关的主机名,这个记录在清理超时或错误的TCPRelayHandler时,用来清理DNSResolver中相关记录时使用的。
接下来我们关注TCPRelayHandler的回调函数是如何实现的:
class TCPRelayHandler(object):
def _handle_dns_resolved(self, result, error): # callback((hostname, ip), None)
if error:
addr, port = self._client_address[0], self._client_address[1]
logging.error('%s when handling connection from %s:%d' %
(error, addr, port))#二次查询没有结果 callback((hostname, None),Exception('unknown hostname %s' % hostname))
self.destroy()#没查到 毁了
return
if not (result and result[1]):
self.destroy()
return
ip = result[1]#local server是ip直接拿到就是ip地址
self._stage = STAGE_CONNECTING
remote_addr = ip#local对应于server的ip 是在handle——addr里设置的
if self._is_local:
remote_port = self._chosen_server[1]
else:
remote_port = self._remote_address[1]
if self._is_local and self._config['fast_open']:
# for fastopen:
# wait for more data arrive and send them in one SYN
self._stage = STAGE_CONNECTING
# we don't have to wait for remote since it's not
# created
self._update_stream(STREAM_UP, WAIT_STATUS_READING)#监听local socket的读事件
#在handle stage addr中 设置是 self._update_stream(STREAM_UP, WAIT_STATUS_WRITING)#未连接远端 实际上localsocket啥也不监听 remote还没连接 状态转入dns
#此时开始处理local socket的可读事件
# TODO when there is already data in this packet
else:
# else do connect
remote_sock = self._create_remote_socket(remote_addr,
remote_port)#建立连接 返回的是设置好的套接字 未连接 这里已经将到remote的socket的文件描述符写入TCPRelay的文件描述符到处理器的映射字典里
try:
remote_sock.connect((remote_addr, remote_port))#建立连接
except (OSError, IOError) as e:
if eventloop.errno_from_exception(e) == \
errno.EINPROGRESS:#仍在进行
pass
self._loop.add(remote_sock,
eventloop.POLL_ERR | eventloop.POLL_OUT,
self._server)#进入监听remote socket的可写状态
self._stage = STAGE_CONNECTING
self._update_stream(STREAM_UP, WAIT_STATUS_READWRITING)#remote:io local:in
self._update_stream(STREAM_DOWN, WAIT_STATUS_READING)
# 在handle stage addr中 设置是 self._update_stream(STREAM_UP, WAIT_STATUS_WRITING)#未连接远端 实际上localsocket啥也不监听 remote还没连接 状态转入dns
# 此时开始处理local socket的可读事件 remote socket的可读可写事件
简化后:
class TCPRelayHandler(object):
def _handle_dns_resolved(self, result, error): # callback((hostname, ip), None)
ip = result[1]#local server是ip直接拿到就是ip地址
self._stage = STAGE_CONNECTING
remote_addr = ip #local对应于server的ip 是在handle——addr里设置的
if self._is_local:
remote_port = self._chosen_server[1]
else:
remote_port = self._remote_address[1]
remote_sock = self._create_remote_socket(remote_addr, remote_port)#建立连接 返回的是设置好的套接字 未连接 这里已经将到remote的socket的文件描述符写入TCPRelay的文件描述符到处理器的映射字典里
try:
remote_sock.connect((remote_addr, remote_port))#建立连接
self._loop.add(remote_sock,eventloop.POLL_ERR | eventloop.POLL_OUT,self._server)#进入监听remote socket的可写状态
回调函数执行,也就是提取出解析得到的ip地址,结合对应的端口(sslocal由配置文件读取,实际是ssserver服务监听的端口,ssserver由sslocal传过去的数据读取),建立套接字(也就是上图中的remote socket),并将该套接字的可写加入loop的监听事件中,将处理器(Handler)注册为TCPRelay实例;此外在_create_remote_socket函数执行时,也完成了将remote socket向TCPRelay实例注册的过程,可以由套接字找到对应的TCPRelayHandler。这样当remote socket套接字发生事件时,就可以loop将事件分发给TCPRelay,进而分发到TCPRelayHandler进行处理。
我们已经分析了什么情况会发送DNS请求和回调函数的实现,接下来一个需要衔接起来的问题就是:在本地缓存没有找到记录而向DNS服务器发出请求时,如何从DNS服务器的应答转换到回调函数的调用?这一部分实际先前已经提到,也就是事件的处理部分,这里我们再次回顾。
class DNSResolver(object):
def handle_event(self, sock, fd, event):#针对不同情况对不同的事件处理
data, addr = sock.recvfrom(1024)
self._handle_data(data)#这是收到回复数据的处理
def _handle_data(self, data):
response = parse_response(data)
hostname = response.hostname
for answer in response.answers:
if answer[1] in (QTYPE_A, QTYPE_AAAA) and answer[2] == QCLASS_IN:
ip = answer[0]
break
self._cache[hostname] = ip
self._call_callback(hostname, ip)
def _call_callback(self, hostname, ip, error=None):
callbacks = self._hostname_to_cb.get(hostname, [])
for callback in callbacks:
callback((hostname, ip), error)
DNS请求发送后,local socket也不再接收数据(避免DNS解析失败而无谓的占用系统资源,具体在下一节数据流的变化详细说明,这里做个大概说明),这时候loop需要监听的事件,只有DNSResolver发送DNS请求的套接字的可读事件。这个可读事件一旦发生,正常情况就是DNS服务器返回了应答。loop根据套接字将这个事件分发到DNSResolver实例,DNSResolver实例通过handle_event函数调用了_handle_data函数处理数据,而_handle_data函数会解析返回的DNS报文,并将解析结果传入这个主机名相关的处理器(TCPRelayHandler实例)逐个进行回调,从而实现DNS解析完成后对各个连接,也就是TCPRelayHandler的通知。
这里对如何构造和解析DNS报文进行分析,可以加深对DNS协议的理解。先回顾一下这次学到的有关DNS的知识,接着回顾DNS请求报文的构造,最后回顾DNS响应的解析。
DNS规范主机名的要求
由chatgpt生成的一段描述,比我自己说清楚多了:
- 字符范围: 允许使用的字符包括字母(A-Z,不区分大小写)、数字(0-9)和连字符(-)。
- 长度限制: 主机名可以由多个标签组成,每个标签最长为63个字符。完整的域名长度不超过255个字符。
- 合法性: 主机名不能以连字符开头或结尾,标签之间必须用点号(.)分隔。
- 大小写不敏感: DNS主机名是大小写不敏感的,意味着字母的大小写不影响其解析或识别。
- 合法字符: 主机名中只允许使用特定的字符集。其他特殊字符如下划线、空格等是不允许的。
- 符合DNS命名约定: 主机名必须符合DNS的命名约定,以确保在DNS系统中能够正确解析和识别。
那么可以通过正则表达式实现,得到一个基于python的正则表达式程序[^11]
import re
def is_valid_hostname(hostname):
if len(hostname) > 255:
return False
if hostname[-1] == ".":
hostname = hostname[:-1] # strip exactly one dot from the right, if present
allowed = re.compile("(?!-)[A-Z\d-]{1,63}(?<!-)$", re.IGNORECASE)
return all(allowed.match(x) for x in hostname.split("."))
这保证了每个标签:
- 至少包含一个字符,最多 63 个字符
- 只包含允许的字符
- 不以连字符开头或结尾
而对于正则表达式,具体含义如下[^12]:
(?!-):这是一个负向零宽度正预测先行断言,确保字符串不以连字符开头(否定匹配"-")。[A-Z\d-]{1,63}:匹配长度为 1 到 63 的字符序列,包括大写字母、数字和连字符。(?<!-):这是一个负向零宽度后发断言,确保字符串不以连字符结尾(否定匹配"-")。$:锚点,匹配字符串的末尾。
DNS报文的格式
这里只涉及ipv4/ipv6地址查询的基本内容,多了东西就太多了。根据rfc1035,一个dns报文会有五个部分,其中一些部分会在特定部分为空,其中格式是
整体结构
+---------------------+
| Header |
+---------------------+
| Question | the question for the name server
+---------------------+
| Answer | RRs answering the question
+---------------------+
| Authority | RRs pointing toward an authority
+---------------------+
| Additional | RRs holding additional information
+---------------------+其中RR指代Resource Record(资源记录)。头部(Header)无论请求或者回答都会出现,报文头部包括字段,指明了剩余部分中的哪些是存在的,也指明了消息是查询还是回复,是标准查询还是其他操作码等等。
Header 头部结构
而头部(Header)是12个字节,6行各2字节,具体展开来说:
1 1 1 1 1 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| ID |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
|QR| Opcode |AA|TC|RD|RA| Z | RCODE |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| QDCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| ANCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| NSCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| ARCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+其中,QR取0,表示请求;取1,表示回复。
RD取1,请求服务器迭代查询。
QDCOUNT,问题部分的条目数。
ANCOUNT,回答的资源记录数。
问题部分结构
问题部分格式,这里包含QDCOUNT(通常是1)个条目,每个条目有如下的格式:
1 1 1 1 1 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| |
/ QNAME /
/ /
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| QTYPE |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| QCLASS |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+其中 QNAME是符合之前提到规范主机名要求的要查询的域名。
QTYPE是请求记录的类型,这里主要用1(查询A记录,也就是域名的ipv4地址)和28(查询AAAA记录,也就是域名的ipv6地址),回复需要了解的可能会有5(CNAME,别名记录)。
QCLASS是请求的类别,这里只用1,代表是查询的是Internet(互联网)中的数据。
资源记录格式
在 DNS(Domain Name System,域名系统)中,资源记录(Resource Record,RR)是一种记录类型,用于存储特定域名相关的信息。每个资源记录包含了特定类型的数据,用于描述一个特定域名的属性。
资源记录(RR)由多个字段组成,其中包括:
- Name Field(名称字段): 指定了资源记录对应的域名或子域名。
- Type Field(类型字段): 指定了记录的类型,比如 A、CNAME、MX 等,代表记录的用途或含义。
- Class Field(类字段): 通常指定为 IN(Internet)表示互联网上的资源记录。
- TTL Field(生存时间字段): 指定了这条记录在缓存中可以存在的时间,以秒为单位。
- RD Length Field(数据长度字段): 指定了资源数据的长度。
- RData Field(资源数据字段): 包含了特定类型记录的数据,比如 IP 地址、域名等。
而资源记录(Resource Records,RR)是构成 DNS 回复报文的重要组成部分之一,当客户端向 DNS 服务器发送查询请求时,请求中包含了关于特定域名的查询信息。DNS 服务器在响应时会构建一个回复报文,这个回复报文包含了查询的答案,而这些答案通常以资源记录的形式存在。
回答部分、授权部分和附加部分都共享相同的格式:它们由可变数量的资源记录组成,而这些记录的数量由报文头部对应的计数字段指定。每个资源记录都具有以下格式:
1 1 1 1 1 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| |
/ /
/ NAME /
| |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| TYPE |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| CLASS |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| TTL |
| |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| RDLENGTH |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--|
/ RDATA /
/ /
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+其中,NAME是与此资源记录相关的域名,具体出现的形式举例,其中域名F.ISI.ARPA是在报文偏移20处开始:
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
20 | 1 | F |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
22 | 3 | I |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
24 | S | I |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
26 | 4 | A |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
28 | R | P |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
30 | A | 0 |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+TYPE指定了记录的类型,这里使用1(查询A记录,也就是域名的ipv4地址)和28(查询AAAA记录,也就是域名的ipv6地址)。
RD Length Field(数据长度字段),指定了资源数据的长度。这个很重要,一来用这个长度取出A记录和AAAA记录的ip地址,二来可以用这个长度知道对应记录何时结束,进而可以解析下一条RR记录。
一个DNS查询请求的实例
这样讲可能对不熟悉DNS的人来说,还是不太直观,我们用wireshark抓个包显式的分析一下。
这是请求的,我们查询www.baidu.com的ip地址
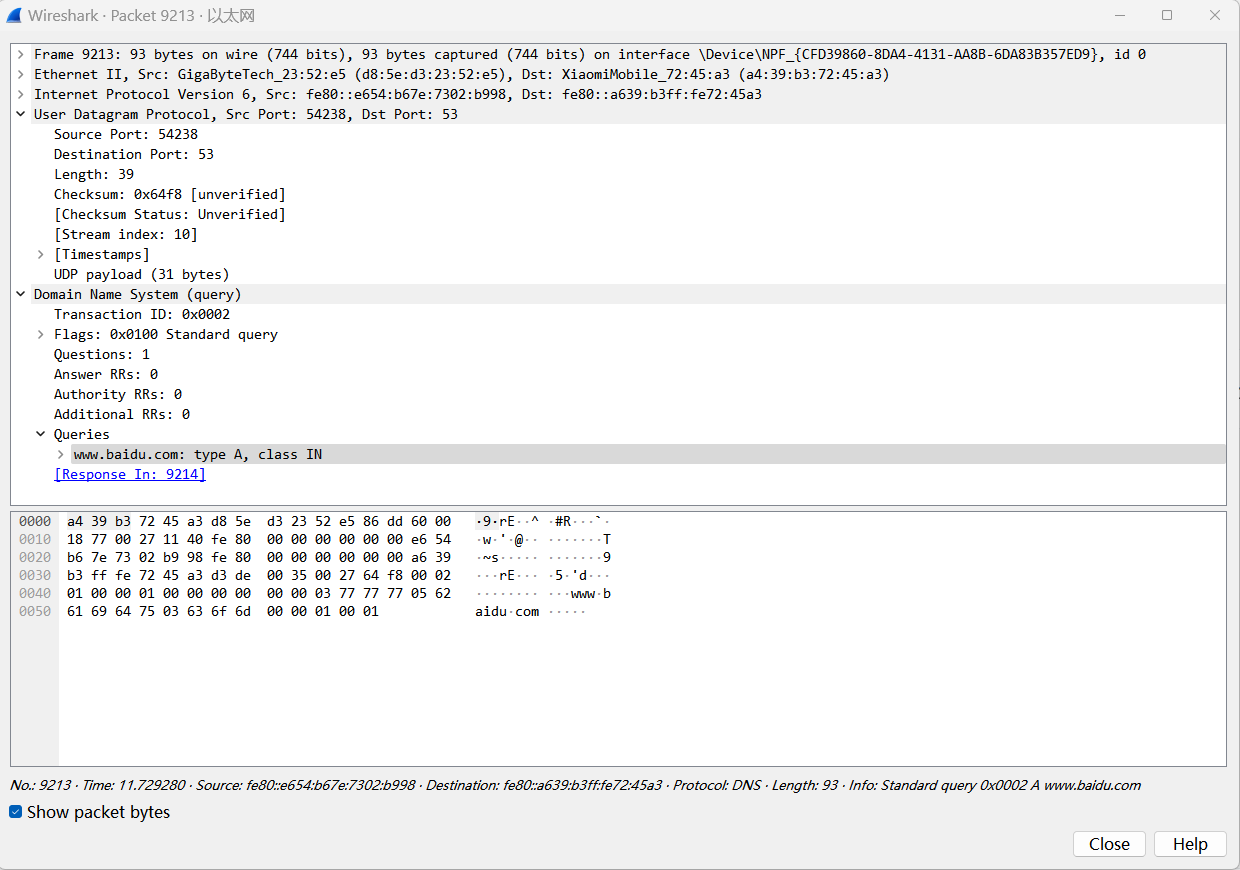
1 1 1 1 1 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0| (请求)编号为2,Shadowsocks是生成一个随机数
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
|0 | 0 0 0 0|0 |0 |1 |0 | 0 0 0 | 0 0 0 0| Recursion desired(RD)为1: 请求递归查询
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 1 | 1个问题
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 0 | 后面的都没有
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 0 |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 0 |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
头部这里结束了 这里数据包就到了0040那行 后半段的00 00结束后了 下面就是问题部分了
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 0 0 0 0 0 0 1 1| 0 1 1 1 0 1 1 1| 第一个字节3指明第一个标签长度为3 后面的01110111就是0x77 对应十进制119 是w的ascii码
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 0 1 1 1 0 1 1 1| 0 1 1 1 0 1 1 1| www就结束了
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 0 0 0 0 0 1 0 1| b | 前面字节说明第二个标签长度是5 后面写字母不展开了 是ascii码对应字符
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| a | i |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| d | u |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 0 0 0 0 0 0 1 1| c | 说明下一个标签长度是3 后面是com的aciii码
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| o | m |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 0 0 0 0 0 0 0 0| 0 0 0 0 0 0 0 0| 第一个0说明qname字段结束了 后面的00与01一起是qtype,这里是1,代表查询a记录
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 0 0 0 0 0 0 0 1| 0 0 0 0 0 0 0 0| 前字节的01是qtype的第二个字节 后字节是qclass的第一个字节 与下个0001一起 代表internet查询
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 0 0 0 0 0 0 0 1|
+--+--+--+--+--+--+--+--+这里一共是15行半,也就是31个字节,这与UDP运输层的length字段39相匹配(UDP头固定8个字节长度)。而DNS响应报文会在头部的一些指示有所不同
,比如第三字节开头的QR域设1,指示是响应报文;还会在请求后面追加响应(RR记录),有回答部分、授权部分和附加部分,在Shadowsocks在接收DNS响应时,程序需要将各个部分逐个处理。
我们再把这个请求的响应报文拿出来分析一下,正好引入一个本次学习到的知识:指针压缩。下面是响应报文的图。
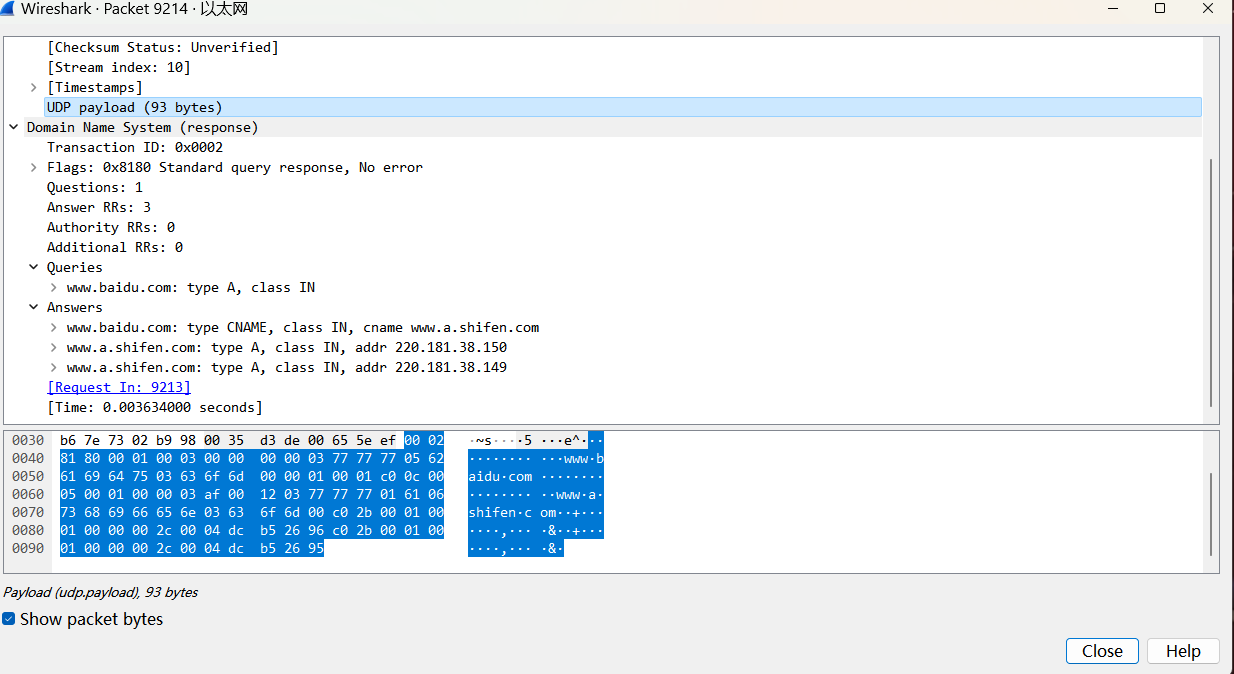
我们先把这个响应报文按照格式展开,因为报文较长,我们这次加上字节数指示,这也是用来解析数据时的偏移值。
1 1 1 1 1 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
0 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0| (响应)编号为2
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
2 |1 | 0 0 0 0|0 |0 |1 |1 | 0 0 0 | 0 0 0 0| QR为1 说明响应;RD为1 请求迭代查询;RA为1 DNS服务器可以递归查询
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
4 | 1 | 1个问题
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
6 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1| 有3个响应的资源记录(RR)值
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
8 | 0 |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
10 | 0 |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
问题部分与之前提出一致 完全照搬过来
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
12 | 0 0 0 0 0 0 1 1| 0 1 1 1 0 1 1 1|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
14 | 0 1 1 1 0 1 1 1| 0 1 1 1 0 1 1 1|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
16 | 0 0 0 0 0 1 0 1| b |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
18 | a | i |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
20 | d | u |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
22 | 0 0 0 0 0 0 1 1| c |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
24 | o | m |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
26 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 0 0 0|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
28 | 0 0 0 0 0 0 0 1| 0 0 0 0 0 0 0 0|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
30 | 0 0 0 0 0 0 0 1| 下个字节应该是第32个字节,紧跟着0x01,但是为了阅读,我们将其另起一行 注意行号的变化。
+--+--+--+--+--+--+--+--+
这里注意偏移的字节值 下面需要与RR记录的规范对比学习
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
31 | 1 1 0 0 0 0 0 0| 0 0 0 0 1 1 0 0| 这里name第一个标签开头是11,超过要求长度的55,说明是指针压缩了,压缩后在12开始
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ 12也就是www.baidu.com的标签第一次出现时的地方
33 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 1 0 1| 指针压缩后,这个name字段就结束了(不需要0),就进入type字段
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ 这里type是5,说明是cname字段
35 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 0 0 1| class字段 1 说明是互联网查询
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
37 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 0 0 0|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ ttl字段,4字节,十进制的943,也就是15min43s
39 | 0 0 0 0 0 0 1 1| 1 0 1 0 1 1 1 1|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
41 | 0 0 0 0 0 0 0 0| 0 0 0 1 0 0 1 0| RDLENGTH字段,取值18,说明后面数据长度18字节
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ 在cname记录下,解析内容用之前解析name的方法一样(用同一个函数完成)
43 | 3 | w |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ 这里简要写一下便于理解 逐bit反而不直观
45 | w | w |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
47 | 1 | a | 字母都是ascii码
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
49 | 6 | s |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
51 | h | i |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
53 | f | e |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
55 | n | 3 |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
57 | c | o |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
59 | m | 0 0 0 0 0 0 0 0| 0说明这个name结束了 一共是18字节 该下一条RR记录了
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ ---------------------下一条----------------
61 | 1 1 0 0 0 0 0 0| 0 0 1 0 1 0 1 1| 开头是11,这里使用了压缩指针,取出43字节处压缩指针,也就是www.a.shifen.com
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
63 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 0 0 1| type:1,说明是ipv4地址
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
65 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 0 0 1| class:1,说明互联网查询
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
67 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 0 0 0|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ ttl:44,说明44s
69 | 0 0 0 0 0 0 0 0| 0 0 1 0 1 1 0 0|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
71 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 1 0 0| RDlength,说明记录长度4(ipv4的固定长度)
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
73 | 1 1 0 1 1 1 0 0| 1 0 1 1 0 1 0 1|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ 这是ipv4地址的二进制表示,220.181.38.150
75 | 0 0 1 0 0 1 1 0| 1 0 0 1 0 1 1 0| 这条RR记录结束了,该下一条了
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ ---------------------下一条----------------
77 | 1 1 0 0 0 0 0 0| 0 0 1 0 1 0 1 1| 压缩指针,指向43字节,www.a.shifen.com
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
79 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 0 0 1| type:1,说明是ipv4地址
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
81 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 0 0 1| class:1,说明互联网查询
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
83 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 0 0 0|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ ttl:44,说明44s
85 | 0 0 0 0 0 0 0 0| 0 0 1 0 1 1 0 0|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
87 | 0 0 0 0 0 0 0 0| 0 0 0 0 0 1 0 0| RDlength,说明记录长度4(ipv4的固定长度)
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
89 | 1 1 0 1 1 1 0 0| 1 0 1 1 0 1 0 1|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ ip地址是220.181.38.149
91 | 0 0 1 0 0 1 1 0| 1 0 0 1 0 1 0 1|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
这与WIreShark指明的UDP载荷字段(UDP头无此数据)93字节一致,说明这么写没啥问题。
对于部分压缩指针的情况,rfc1035有个例子,这里贴上,有了之前的分析看一眼应该就明白了,就是前面是正常的标签,后面可以用压缩指针就不以0b00000000结束,而后加上压缩指针的位置的指示。
例如,域名F.ISI.ARPA 和 FOO.F.ISI.ARPA 和 ARPA 可以打包为如下数据QNAME流(忽略其他报文段)
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
O + + +
F + + +
F + + +
S + BYTE0 + BYTE1 +
E + + +
T + + +
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
20 | 1 | F |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
22 | 3 | I |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
24 | S | I |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
26 | 4 | A |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
28 | R | P |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
30 | A | 0 |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
......
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
40 | 3 | F |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
42 | 0 | 0 |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
44 | 1 1 | 20 |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
......
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
64 | 1 1 | 26 |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
网络传输是按大端序(网络字节序),处理数据时需要有!,这个在相关的函数有写,就不会解析错数据。网络字节序我现在也没有理解透彻,需要进一步学习。
按我现在的理解,在处理87字节处的RDlength字段时,如果指定了网络字节序,那么就可以解析出0b0000000000000100,也就是4字节,不指定可能会按计算机的小端序处理,将数据低位放到较小地址处,也就储存成了0b0000010000000000,解析成1024字节,造成程序运行的错误。可能是因为计算从低位开始,所以小端序效率更高:如果按小端序,先读入了0b00000000,低位是0;再读入了0b00000100,高位是4,那么最终结果就是$4 \times 2^8 = 1024\$。只要指定了网络字节序,就可以取出正确的值。参考资料[^13]
下面就对具体的程序实现进行学习总结。
DNS请求报文发送的程序实现
在socket编程中,UDP层的数据基本都由系统设置,我们需要编程的是UDP数据报的载荷。Shadowsocks主要有两个函数:build_request和DNSResolver类的_send_req函数。
def build_address(address):
address = address.strip(b'.')
labels = address.split(b'.')
results = []
for label in labels:
l = len(label)
if l > 63:
return None
results.append(common.chr(l))#一个字节
results.append(label)
results.append(b'\0')
return b''.join(results)
def build_request(address, qtype):#构造一个请求数据包
request_id = os.urandom(2)#2byte 序号随机生成
header = struct.pack('!BBHHHH', 1, 0, 1, 0, 0, 0)#112222字节 0 QR查询 0000 opcode标准查询 0 响应报文有效果 0 不截断 1可以迭代查询 0相应 000保留取0 0000返回码 无错误 1个问题 0回答 权威服务器条目数 额外信息条目数
#提问只打包了一个题目
addr = build_address(address)#打标签
qtype_qclass = struct.pack('!HH', qtype, QCLASS_IN) #各两个字节
return request_id + header + addr + qtype_qclass
class DNSResolver(object):
def _send_req(self, hostname, qtype):
req = build_request(hostname, qtype)
for server in self._servers:
logging.debug('resolving %s with type %d using server %s', hostname, qtype, server)
self._sock.sendto(req, (server, 53))
这里值得借鉴的是build_address函数,它将一个要查询的主机名打包成符合DNS规范主机名的字节流,以便直接作为载荷发送。完整发送过程很显然是打包了一个主机名的查询,其中各个字段的含义之前学习DNS报文时就已经详细说过了,备注也有相关说明。在打包完DNS请求头部后,请求的三部分作为参数,将要查询的主机名(build_address函数打包的)和查询类型(这里只有A记录或AAAA记录)打包。在send_req函数中,用DNSResolver实例的套接字,向配置文件得到的所有DNS服务器发送查询报文。发送的只有一个请求,不会有多个。
DNS响应报文接收的程序实现
由对DNS报文结构的学习,我们知道了DNS响应报文处理核心内容是解析各个部分的结构,获取其中有关的值。那么有以下几个函数是必要的:
- 解析DNS数据包头(Header),所有报文都有请求头。函数名是`parse_header(data):
- 解析请求,一般回应报文都会包含原问题,可以用来拿到原始请求域名。函数名是
parse_record(data, offset, question=True) - 解析RR记录,也就是DNS服务器返回的记录。函数名是
parse_record(data, offset, question=False) - 解析名称,DNS报文中主机名要按规范主机名格式,要考虑到压缩指针的处理,通过偏移值递归调用获得压缩内容。NAME在请求部分和RR部分都会出现,因此解析每一部分都要用。函数名
parse_name(data, offset) - 解析记录内容,获取RDATA中的ipv4地址/ipv6地址或CNAME记录等,这里需要RR记录的RDLENGTH、TYPE等参数,由解析记录的函数获取。函数名
parse_ip(addrtype, data, length, offset) - 将解析得到的记录整合处理,按照一定简化格式返回处理,上面几个具体功能函数都在这个函数中被调用。函数名
parse_response(data)
def parse_header(data):
if len(data) >= 12:
header = struct.unpack('!HBBHHHH', data[:12])
res_id = header[0]
res_qr = header[1] & 128#10000000 最高位
res_tc = header[1] & 2#10 RD位 1期望递归
res_ra = header[2] & 128#RA位 1 递归可用
res_rcode = header[2] & 15#Rcode位
# assert res_tc == 0
# assert res_rcode in [0, 3]
res_qdcount = header[3]
res_ancount = header[4]
res_nscount = header[5]
res_arcount = header[6]
return (res_id, res_qr, res_tc, res_ra, res_rcode, res_qdcount,
res_ancount, res_nscount, res_arcount)
return None
解析DNS报文头部很容易理解,因为只在报文最前头出现一次,所以也不需要偏移值或者迭代调用,只需要按DNS报文的格式中的Header结构逐比特,提取出各个字段的数据,作为元组返回。
def parse_record(data, offset, question=False):#nlen 是名字的长度
nlen, name = parse_name(data, offset)
if not question:
record_type, record_class, record_ttl, record_rdlength = struct.unpack(
'!HHiH', data[offset + nlen:offset + nlen + 10]
)
ip = parse_ip(record_type, data, record_rdlength, offset + nlen + 10)#从offset + nlen + 10开始 加上record_rdlength ns记录返回了元组(长度,域名)
return nlen + 10 + record_rdlength, \
(name, ip, record_type, record_class, record_ttl) #一条记录的长度,以及一个元组
else:
record_type, record_class = struct.unpack(#这是提问的 没有
'!HH', data[offset + nlen:offset + nlen + 4]#问题的名字还在 没有RDLENGTH和RDATA
)
return nlen + 4, (name, None, record_type, record_class, None, None)
解析记录的函数也比较容易理解,该函数将请求部分和RR部分用一个函数实现,返回值均是这一条记录(一条请求记录/一条RR记录)占了多少字节,(特别说明:每一条记录的长度是不一样的,这是因为NAME的长度和RR记录的长度是可变的,需要解析并进一步处理),这是用来定位下一条记录的位置,方便间接作为偏移值(offset)进行下一步处理;以及一个统一的包含解析结果的元组(请求记录只有三行,故有的赋值None)。
解析记录时先解析NAME的长度和处理后的结果(www.google.com 从标签变成了可读的域名格式),对于请求记录,直接解析相关的部分返回;对于RR记录,还要解析DNS服务器返回的记录值(parse_ip函数)。
def parse_name(data, offset):#返回一个元组(整个记录的长度,别名b'www.google.com')的二进制流 answer的长度和question的长度一致 故可以一直用
p = offset
labels = []
l = common.ord(data[p])
while l > 0:
if (l & (128 + 64)) == (128 + 64):#递归了
# pointer
pointer = struct.unpack('!H', data[p:p + 2])[0]
pointer &= 0x3FFF#取出递归的偏移位置
r = parse_name(data, pointer)
labels.append(r[1])
p += 2#指针就是最后了 直接返回
# pointer is the end
return p - offset, b'.'.join(labels)#返回的是www.google.com这样
else:
labels.append(data[p + 1:p + 1 + l])#从偏移处取出标签
p += 1 + l#更改偏移
l = common.ord(data[p])#取下一个的长度 结束为0
return p - offset + 1, b'.'.join(labels)#一个是直接返回 一个是递归返回 +1是指示结束的0的一个字节长度
解析主机名需要注意到压缩指针的递归调用,因为出现压缩指针后主机名就结束了,所以直接返回,并且长度也不需要额外加1。这里可以感受到规范主机名规定每个标签小于63位的重要性,正是这个规定使得if (l & (128 + 64)) == (128 + 64)可以作为判断压缩指针的条件,这大大的加深了我对DNS协议的理解。还有值得再说一次的是,返回值是在这条offset处开始的记录中主机名占的字节数,而不是主机名完整的长度,所以压缩指针那里是p += 2(压缩指针只占两个字节),我们需要的是每条记录中名字字段占的长度,以便于进一步定位资源和解析,而主机名完整的长度已经没那么重要了,在这里不需要关注。
def parse_ip(addrtype, data, length, offset):
if addrtype == QTYPE_A:
return socket.inet_ntop(socket.AF_INET, data[offset:offset + length])
elif addrtype == QTYPE_AAAA:
return socket.inet_ntop(socket.AF_INET6, data[offset:offset + length])
elif addrtype in [QTYPE_CNAME, QTYPE_NS]:#包里回复报文解析出来的 权威
return parse_name(data, offset)[1]#cname返回cname记录值
else:
return data[offset:offset + length]#SOA直接返回数据 不解析了
解析记录的函数容易理解,通过输入的RDLENGTH(length参数)长度和类型,返回对应的值,ip地址返回可读的地址形式(字符串'111.111.111.1'),CNAME记录返回别名的名字,其他类型原封不动返回(在进一步处理时直接舍弃了)。
def parse_response(data):
try:
if len(data) >= 12:
header = parse_header(data)
if not header:
return None
res_id, res_qr, res_tc, res_ra, res_rcode, res_qdcount, \
res_ancount, res_nscount, res_arcount = header
qds = []
ans = []
offset = 12#去头
for i in range(0, res_qdcount):
l, r = parse_record(data, offset, True)
offset += l#parse_record返回的是字段长度 所以offset要累加 非常漂亮
if r:
qds.append(r)
for i in range(0, res_ancount):
l, r = parse_record(data, offset)#回答 跨过一条
offset += l
if r:
ans.append(r)#回答加入元组
for i in range(0, res_nscount):
l, r = parse_record(data, offset)#名字长度+头长度10+记录长度
offset += l
for i in range(0, res_arcount):
l, r = parse_record(data, offset)
offset += l
response = DNSResponse()#一个类
if qds:
response.hostname = qds[0][0]#www.baidu.com
for an in qds:
response.questions.append((an[1], an[2], an[3]))#None, record_type, record_class 只取这些record_ttl不要了
for an in ans:
response.answers.append((an[1], an[2], an[3]))#ip, record_type, record_class
return response
except Exception as e:
shell.print_exception(e)
return None
整体的解析就很简单了,按照解析头部HEADER(获取各个部分记录的数量),解析请求部分,解析RR记录的部分逐个解析。在这过程中,将parse_record返回的每条记录完整的长度作为offset(偏移)累加值,用来定位下一条记录并下一步解析。最后将请求的记录和回答的记录作为返回值返回,DNSResponse是一个很简单的类,具体实现完整程序有,这里不多说了。
在返回的记录中,Shadowsocks实际上只关注ip地址(ipv4或ipv6),虽然 response.answers中第一个部分可能包含除CNAME、ip地址外的原始记录值(其他类型记录),但是在后面的具体实现中,包括CNAME也被舍弃了,所以这里也不用细究,这只实现了很基础的DNS功能。
DNSResolver在收到DNS服务器的响应报文,执行回调函数handle_event时,需要调用parse_response函数:在得到请求的主机名和解析后的ip地址,就去寻找该主机名对应的回调函数,逐个进行回调,这就是前面提到的事件的处理的内容了。
最后有一个值得注意的事情:sslocal是从配置文件得到ssserver的地址和端口,ssserver是如何得到要远程DNS解析的地址以及要连接的端口?这里就要从socks5代理的协议说起了,简而言之,socks5在client和sslocal之间存在,会将client的目的地址按照socks5协议的固定格式发送给sslocal;sslocal在修剪这个固定格式后,直接用tcp流发送给ssserver,ssserver最先收到的几个字节就包含了目的站点的信息(先忽视加密方法的初始向量(initial vector))。下面我们对socks5协议进行简单学习,在了解后再进行数据流转发部分的分析。
Socks5协议的简要介绍
个人的一点碎碎念
这里记录一下自己的理解,不保证准确,如果有人看当个消遣就好。
首先从RFC1928的Introduction聊起,我这里直接翻译了,有需要看原文的请从参考连接进入[^5]:
网络防火墙的使用越来越普遍,这些系统能有效地隔离组织内部的网络结构与外部网络(比如互联网)。这些防火墙系统通常作为网络之间的应用层网关,通常提供受控的TELNET、FTP和SMTP访问。随着更复杂的应用层协议的出现,这些协议旨在促进全球信息发现,因此需要提供一个通用的框架,使这些协议能够透明且安全地穿越防火墙。
同时,也存在对这种穿越进行强大认证的需求,要以尽可能细致的方式进行。这一要求源于意识到不同组织间会形成客户端-服务器关系,这些关系需要被控制并经常需要进行强大认证。
所描述的协议旨在为TCP和UDP领域的客户端-服务器应用程序提供一个框架,以便方便且安全地使用网络防火墙的服务。该协议在概念上是应用层和传输层之间的“垫层”,因此不提供网络层网关服务,比如转发ICMP消息。
这里让我想起了阅读计算机网络-自顶向下方法中的有关应用程序网关的相关内容(P427)。
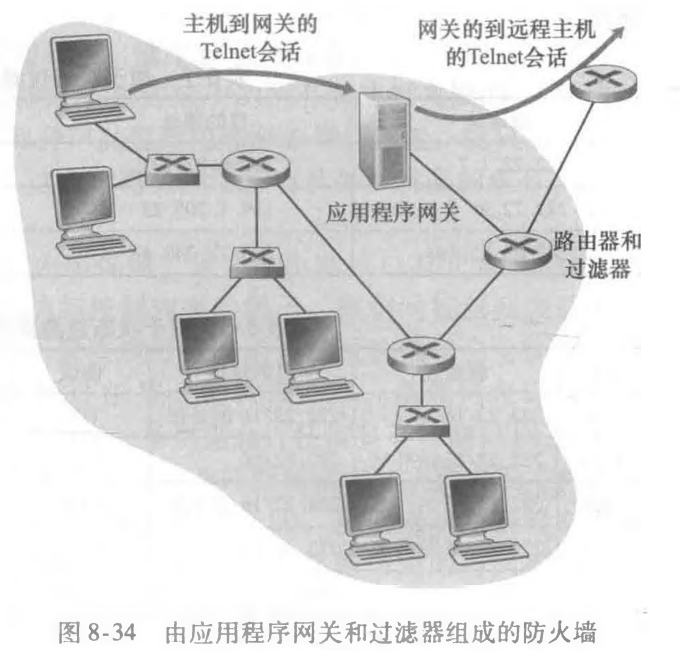
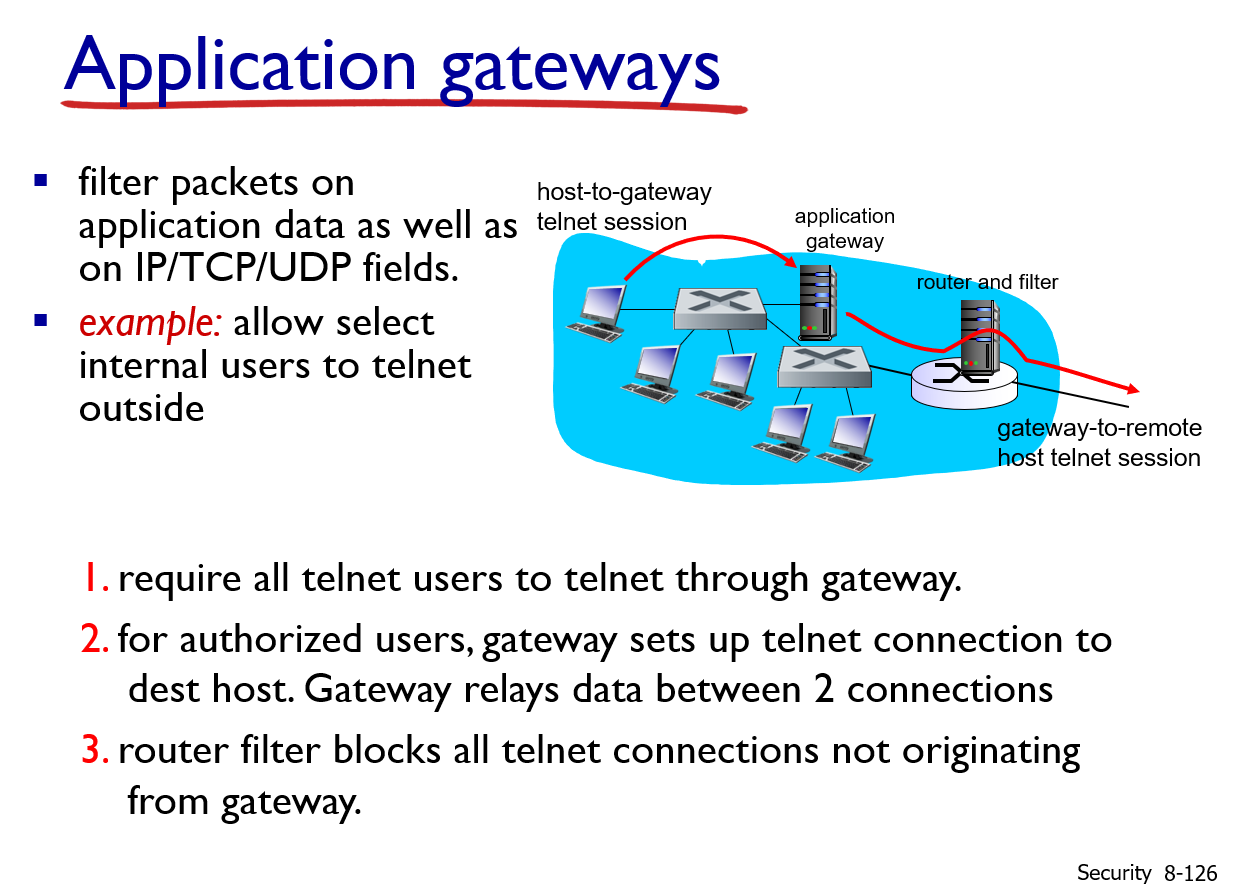
在上面的例子中,我们已经看到了分组级过滤使得一个机构可以根据IP的内容和 TCP/UDP首部(包括IP地址、端口号和ACK比特)执行粗粒度过滤。但是如果一个机构仅为一个内部用户的受限集合(与IP地址情况正相反)提供Telnet服务该怎样做呢?如果该机构要这些特权用户在允许创建向外部的Telnet会话之前首先鉴别他们自己该怎样做呢?这些任务都超出了传统过滤器和状态过滤器的能力。的确,有关内部用户的身份信息是应用层数据,并不包括在IP/TCP/UDP首部中。
为了得到更高水平的安全性,防火墙必须把分组过滤器和应用程序网关结合起来。应 用程序网关除了看IP/TCP/UDP首部外,还基于应用数据来做策略决定。一个应用程序网关(application gateway)是一个应用程序特定的服务器,所有应用程序数据(入和出的) 都必须通过它。多个应用程序网关可以在同一主机上运行,但是每一个网关都是有自己的进程的单独服务器。
为了更深入地了解应用程序网关,我们来设计一个防火墙,它只允许内部客户的受限集合向外Telnet,不允许任何外部客户向内Telnet。这一策略可通过将分组过滤(在一台路由器上)和一个Telnet应用程序网关结合起来实现,如图8-34所示。路由器的过滤器配置为阻塞所有Telnet连接,但从该应用程序网关IP地址发起的连接除外。 这样的过滤器配置迫使所有向外的 Telnet连接都通过应用程序网关。现在考虑一个要向外部Telnet的内部用户。这个用户必须首先和应用程序网关建立一个Telnet会话。在网关(网关监听进入的Telnet会话)上一直运行的应用程序提示用户输入用户ID和口令。当这 个用户提供这些信息时,应用程序网关 检查这个用户是否得到许可向外Telnet。如果没有,网关则中止这个内部用户向该网关发起的Telnet连接。如果该用户得到许可,则这个网关:①提示用户输入它所要连接的外部主机的主机名;②在这个网关和某外部主机之间建立一个Telnet会话;③将从这个用户到达的所有数据中继到该外部主机,并且把来自这个外部主机的所有数据都中继给这个用户。所以,该Telnet应用程序网关不仅执行用户授权,而 且同时充当一个Telnet服务器和一个Telnet客户,在这个用户和该远程Telnet服务器之间中继信息。注意到过滤器因为该网关发起向外部的Telnet连接,将允许执行步骤②。
内部网络通常有多个应用程序网关,例如Telnet、HTTP、FTP和电子邮件网关。事实上,一个机构的邮件服务器(见2. 3节)和Web高速缓存都是应用程序网关。
应用程序网关也有其缺陷。首先,每一个应用程序都需要一个不同的应用程序网关。 第二,因为所有数据都由网关转发,付出的性能负担较重。当多个用户或应用程序使用同一个网关计算机时,这成为特别值得关注的问题。最后,当用户发起一个请求时,客户软件必须知道如何联系这个网关,并且必须告诉应用程序网关如何连接到哪个外部服务器。
以及原书配套的两页PPT:

这里想记录的是自己对socks5协议出现背景的一点理解:socks5是为了完善网络防火墙系统并提供一个功能上类似于应用程序网关的通用的框架协议。chatgpt认为我的说法是基本上是对的,我将他的描述记录下来(因为之前是我自己的理解,所以就要留下来):”Socks5是一种网络协议,用于在客户端和服务器之间传输数据,允许客户端通过防火墙和代理服务器与远程服务器进行通信。它提供了一种通用的框架,允许不同的应用程序通过代理服务器进行连接,从而实现了网络数据的安全传输和跨防火墙的访问。这个协议的设计使得它能够支持各种类型的网络流量,从而成为一个相对通用的代理协议。”socks5可以将各种应用程序的数据发送给代理服务器,而代理服务器在防火墙的白名单中,这样就可以在将内网其他设备的流量禁止的情况下,实现了应用程序的跨防火墙通信;而内网设备是否有权使用这个代理服务器,是用socks5的认证机制实现的。
SOCKS5协议有认证机制,通过用户名/密码认证,只有拥有有效凭证的用户才能连接到SOCKS5代理服务器。这种认证机制有助于限制代理服务器的访问,防止未经授权的用户使用代理服务器访问互联网。这种访问控制可以有助于保护网络安全,防止滥用代理服务器进行恶意活动或未经授权的访问。也就是说,认证提供了一层额外的安全性,确保只有经过授权的用户才能使用代理服务器进行连接和通信。朴素的说,就是socks5 client需要向socks5 server用密码登录一下,让socks5 server明白这个client是有资格使用本server的。回到Shadowsocks的socks5具体部分,Shadowsocks只接受无认证方式,其他认证方式都会返回错误。不要将Socks5的加密认证和Shadowsocks常说的加密混淆了:socks5在Shadowsocks没有用任何加密认证方式;Shadowsocks对数据流的加密使用的是对称加密算法(比如AES算法),二者完全不是一码事。
这里记录一下自己理解出现的误区,我误认为socks5协议和ipsec协议的ESP隧道模式一样,会将每个数据包加密并嵌入到一个新的IP数据包中(这个新的IP数据包包含了额外的IPsec头部和ESP头部)如下图(折叠内容内)。而socks5实际上并不提供对数据的加密,如果需要加密要采取其他手段(比如Shadowsocks采用的在应用层加密数据流)。
下面这个例子是ipsec模拟实验的一个例子[^14],其中路由器R1和R2配置了IPSEC,通过R0类似于通过正常的公用网络(网络核心),没有有关于IPSEC的配置。和本文没啥关系,整理材料看到的就顺手截两张图放上来了。
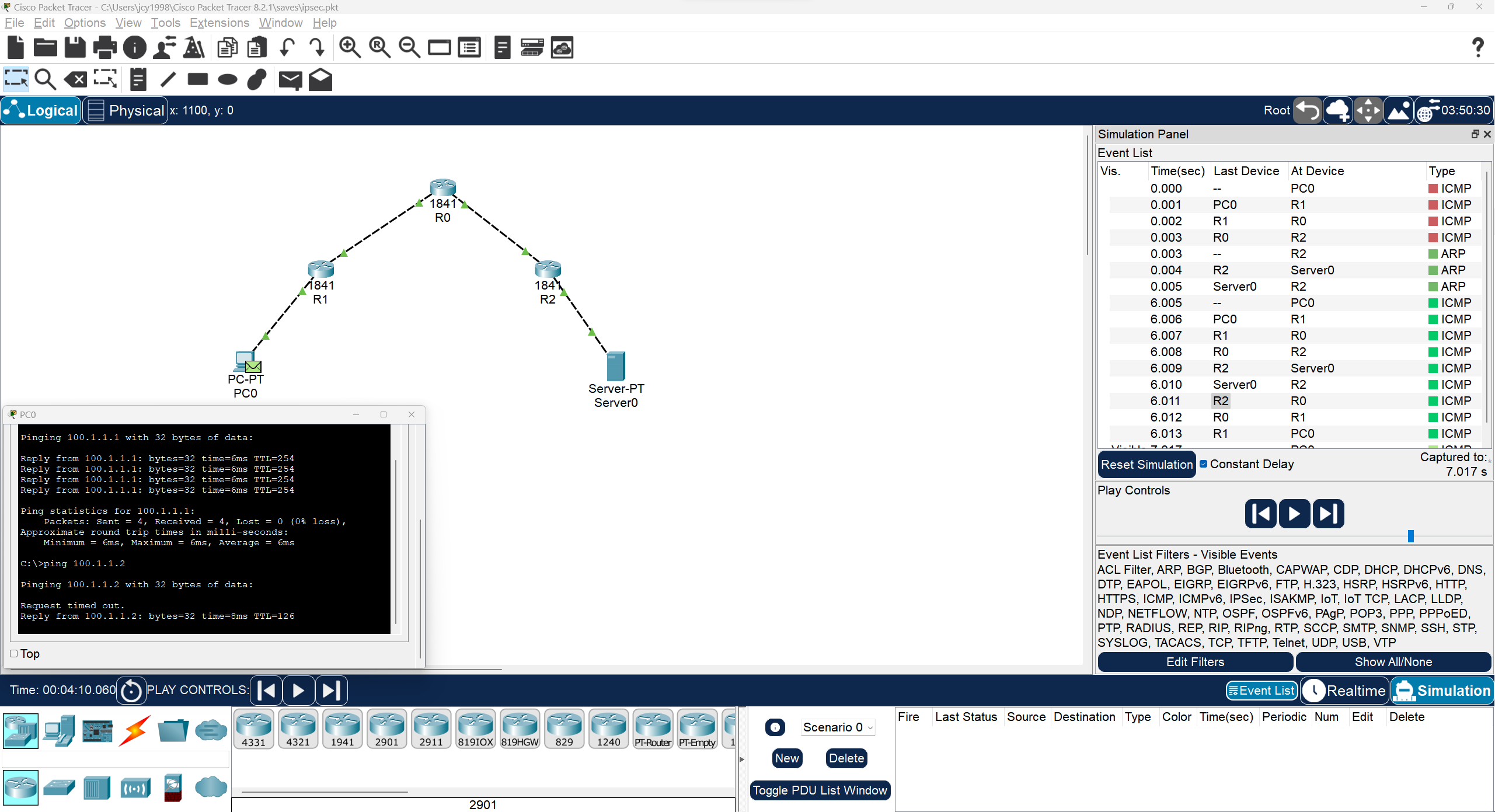

其中server0回应ICMP报文的数据包在经过路由器R2后被IPSEC包装了,包装成下图(注意ip地址和载荷的变化)

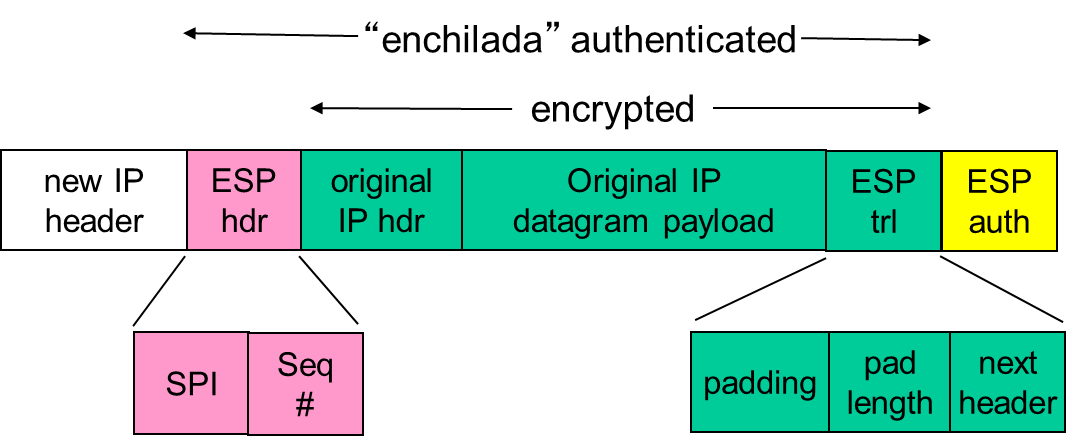
如果看到这几张图如果读者对IPSEC感兴趣了,那可以看看RFC4301[^15]和RFC4309[^16] ,这里作为学习过程中的一点想法和记录。
接下来有关socks5的描述直接摘自[^17],这里包含了socks5的基本流程和数据包结构,也是Shadowsocks实际程序实现时需要用到的部分,前面的个人碎碎念只是用作记录。
握手阶段
客户端和服务器在握手阶段协商认证方式,比如:是否采用用户名/密码的方式进行认证,或者不采用任何认证方式。
客户端发送给服务器的消息格式如下(数字表示对应字段占用的字节数):
+----+----------+----------+
|VER | NMETHODS | METHODS |
+----+----------+----------+
| 1 | 1 | 1~255 |
+----+----------+----------+VER字段是当前协议的版本号,也就是5;NMETHODS字段是METHODS字段占用的字节数;METHODS字段的每一个字节表示一种认证方式,表示客户端支持的全部认证方式。
服务器在收到客户端的协商请求后,会检查是否有服务器支持的认证方式,并返回客户端如下格式的消息:
+----+--------+
|VER | METHOD |
+----+--------+
| 1 | 1 |
+----+--------+对于 shadowsocks 而言,返回给客户端的值只有两种可能:
0x05 0x00:告诉客户端采用无认证的方式建立连接;0x05 0xff:客户端的任意一种认证方式服务器都不支持。
举个例子,就 shadowsocks 而言,最简单的握手可能是这样的:
client -> ss: 0x05 0x01 0x00
ss -> client: 0x05 0x00如果客户端还支持用户名/密码的认证方式,那么握手会是这样子:
client -> ss: 0x05 0x02 0x00 0x02
ss -> client: 0x05 0x00如果客户端只支持用户名/密码的认证方式,那么握手会是这样子:
client -> ss: 0x05 0x01 0x02
ss -> client: 0x05 0xff建立连接
完成握手后,客户端会向服务器发起请求,请求的格式如下:
+----+-----+-------+------+----------+----------+
|VER | CMD | RSV | ATYP | DST.ADDR | DST.PORT |
+----+-----+-------+------+----------+----------+
| 1 | 1 | 1 | 1 | Variable | 2 |
+----+-----+-------+------+----------+----------+`CMD字段:command` 的缩写,shadowsocks 只用到了:0x01:建立 TCP 连接0x03:关联 UDP 请求
RSV字段:保留字段,值为0x00;ATYP字段:address type的缩写,取值为:0x01:IPv40x03:域名0x04:IPv6
DST.ADDR字段:destination address的缩写,取值随ATYP变化:ATYP == 0x01:4 个字节的 IPv4 地址ATYP == 0x03:1 个字节表示域名长度,紧随其后的是对应的域名ATYP == 0x04:16 个字节的 IPv6 地址
DST.PORT字段:目的服务器的端口。
在收到客户端的请求后,服务器会返回如下格式的消息:
+----+-----+-------+------+----------+----------+
|VER | REP | RSV | ATYP | BND.ADDR | BND.PORT |
+----+-----+-------+------+----------+----------+
| 1 | 1 | 1 | 1 | Variable | 2 |
+----+-----+-------+------+----------+----------+REP字段:用以告知客户端请求处理情况。在请求处理成功的情况下,shadowsocks 将这个字段的值设为0x00,否则,shadowsocks 会直接断开连接;- 其它字段和请求中字段的取值类型一样。
举例来说,如果客户端通过 shadowsocks 代理 127.0.0.1:8000 的请求,那么客户端和 shadowsocks 之间的请求和响应是这样的:
# request: VER CMD RSV ATYP DST.ADDR DST.PORT
client -> ss: 0x05 0x01 0x00 0x01 0x7f 0x00 0x00 0x01 0x1f 0x40
# response: VER REP RSV ATYP BND.ADDR BND.PORT
ss -> client: 0x05 0x00 0x00 0x01 0x00 0x00 0x00 0x00 0x10 0x10这里 0x7f 0x00 0x00 0x01 0x1f 0x40 对应的是 127.0.0.1:8000。需要注意的是,当请求中的 CMD == 0x01 时,绝大部分 SOCKS5 客户端的实现都会忽略 SOCKS5 服务器返回的 BND.ADDR 和 BND.PORT 字段,所以这里的 0x00 0x00 0x00 0x00 0x10 0x10 只是 shadowsocks 返回的一个无意义的地址和端口。
传输阶段
SOCKS5 协议只负责建立连接,在完成握手阶段和建立连接之后,SOCKS5 服务器就只做简单的转发了。假如客户端通过 shadowsocks 代理 google.com:80(用 remote 表示),那么整个过程如图所示:
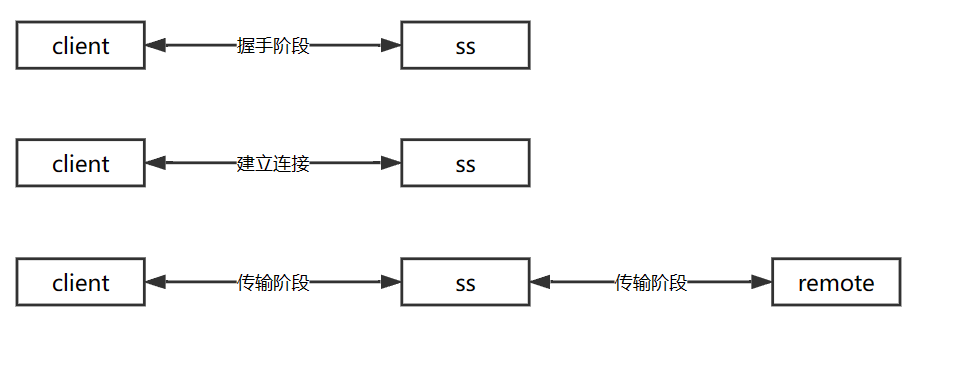
整个过程中发生的传输可能是这样的:
# 握手阶段
client -> ss: 0x05 0x01 0x00
ss -> client: 0x05 0x00
# 建立连接
client -> ss: 0x05 0x01 0x00 0x03 0x0a b'google.com' 0x00 0x50
ss -> client: 0x05 0x00 0x00 0x01 0x00 0x00 0x00 0x00 0x10 0x10
# 传输阶段
client -> ss -> remote
remote -> ss -> client
...b'google.com' 表示 google.com 对应的 ASCII 码。
有一点需要提一下:代理和Shadowsocks的代理是不一样的。比如,下图是普通的 SOCKS5 代理:

而能Shadowsocks的 SOCKS5 代理是下图这种结构:

可以看出来,SOCKS5 服务器的实现被拆分成了两部分:
- sslocal 负责与 SOCKS5 客户端进行 SOCKS5 协议相关的通讯(握手并建立连接),在建立连接后将 SOCKS5 客户端发来的数据加密并发送给 ssserver;
- ssserver 起到一个中继的作用,负责解密以后将数据转发给目标服务器,并不涉及 SOCKS5 协议的任何一部分。
其中一个重要的环节就是加密解密——数据经过 sslocal(本机)加密以后转发给 ssserver(VPS),这也是普通代理和Shadowsocks的代理的区别。
----------引用结束----------------------
通过建立连接时client向sslocal发送的数据,sslocal按照socks5协议解析后就知道了想要访问的目标服务器的地址和端口,也就可以传给ssserver,使得ssserver与目标服务器建立连接了。在传输阶段,Shadowsocks是用socks5协议从client(如浏览器)获取数据流,在加密后发给ssserver(已经不是socks5了),ssserver在解密后(这时实际就是client通过socks5发送的数据流),再转发给目标服务器。容易引起混淆的一点:每条TCP连接都需要经历一次socks5的握手、建立连接和传输阶段,这在程序实现中,是sslocal监听端口,对每个传入的连接套接字,都建立一个TCPRelayHandler来实现的,这也意味着,每个TCPRelayHandler在要转发数据时,都需要对握手、建立连接和传输阶段进行处理。
socks5抓包实例分析
作为示例,抓一次包看看,可以加深理解。
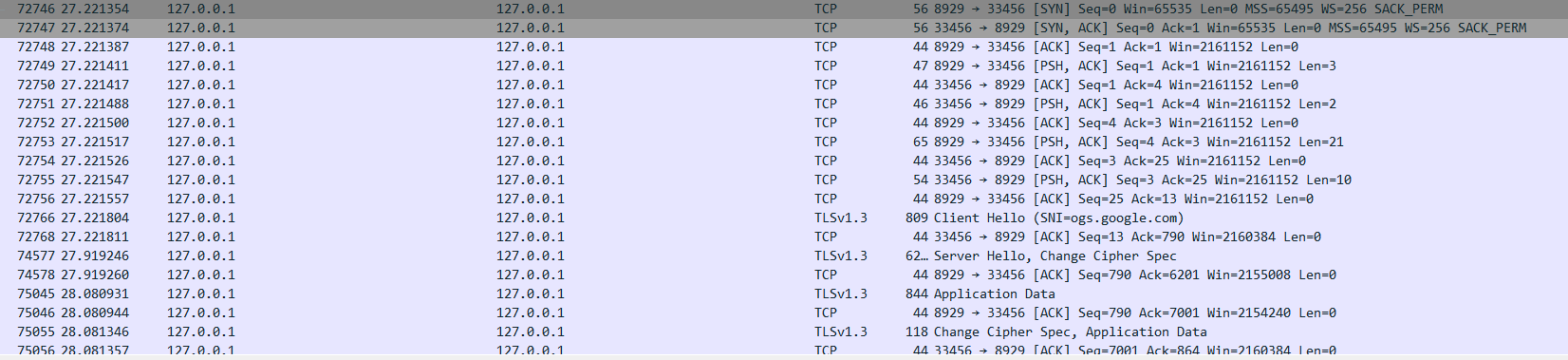
这是一个client与sslocal通信的实例,其中sslocal监听33456端口,为方便关注前面的握手阶段和建立连接阶段,追踪TCP流并设置raw格式,这里返回的bind port是0x0000,这个值前面提了没什么用,我电脑上用的也是较新版本的客户端,可能是版本不同的影响,上边引用的socks5解析也有说也有部分 SOCKS5 服务器的实现返回全零。
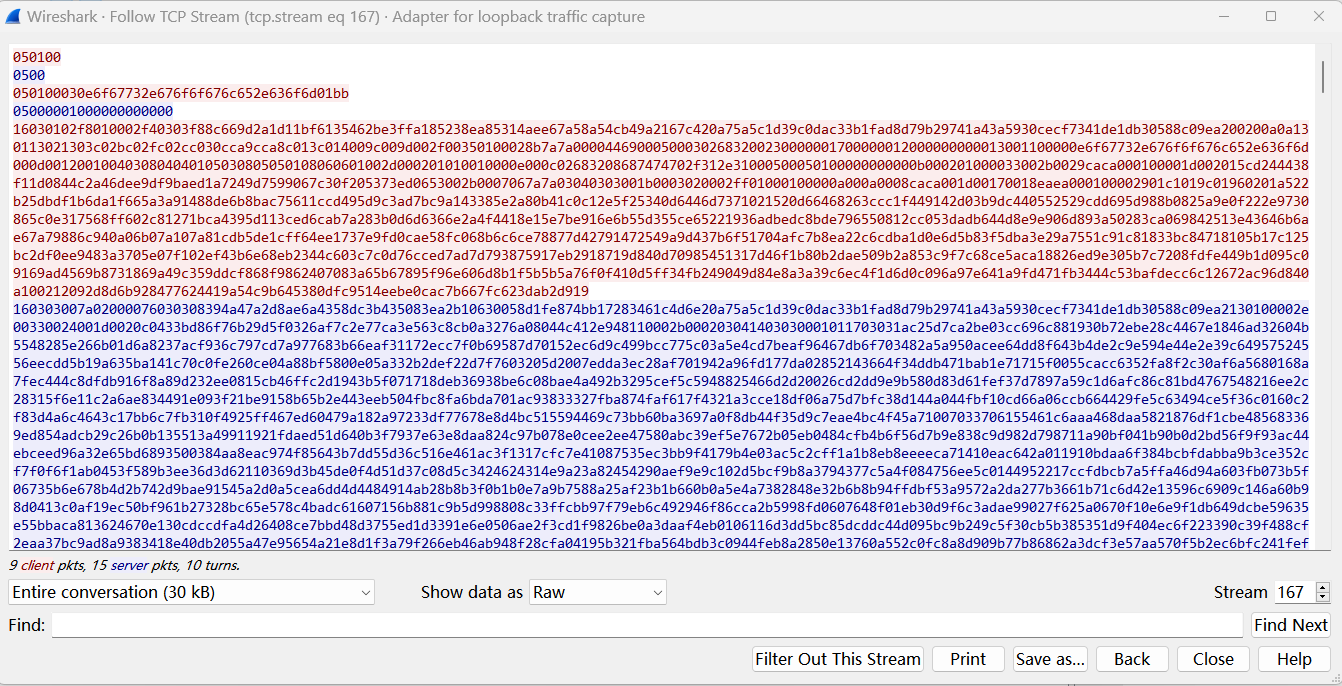
可以发现1、2行就是前面提到的握手阶段,3、4行就是建立连接阶段。针对第三行我们仔细阅读下:
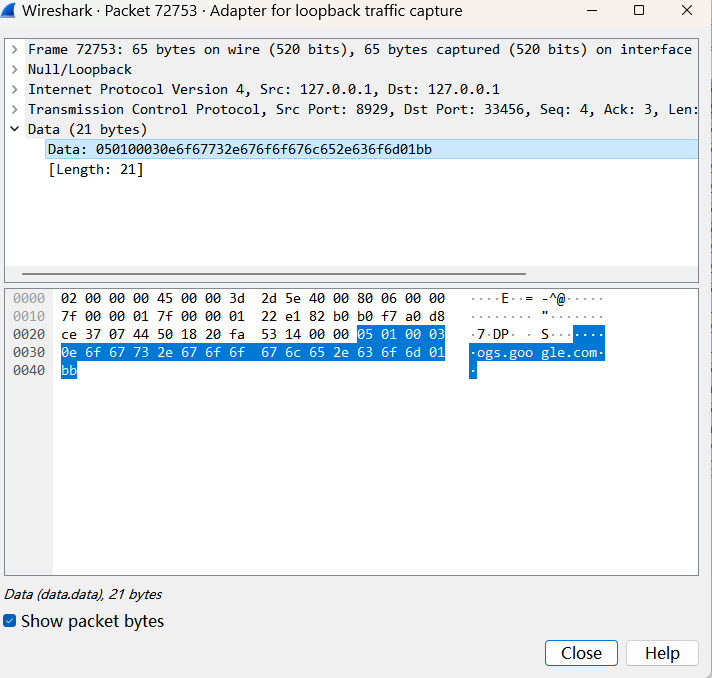
050100030e6f67732e676f6f676c652e636f6d01bb
client -> ss: 0x05 0x01 0x00 0x03 0x0e b'ogs.google.com' 0x01 0xbbwireshark已经按照ascii读出了ogs.google.com,0x0e也就是14的长度,也就是前面域名的程度。端口号0x01 0xbb,十进制443,也就说明这是要与ogs.google.com的443端口进行通信,实际上就是https。由抓包图可知,27.22s到27.91s足足有0.7s才得到返回的第一个数据包,而之后数据包吞吐间隔都远小于这个值,这实际上是因为,在这个过程过程中,ssserver要进行DNS的远程解析,解析完成建立连接后,将client hello的数据转发过去,目标服务器再经ssserver转发回来,所以时间间隔最大,点出来的两个点(这个将在数据流的转发详细分析,这里做个概述,引出问题)。
由数据包分析可知,之后就是完完全全的数据流转发了,就是正常的https握手,sslocal和ssserver在其中完成数据中继的过程。从抓包分析也可以知道,你的中转服务器上(如VPS),是可以知道的访问的主机名的(通过socks5的建立连接阶段)。在传输过程中,http对VPS更是明文,https也可以通过sni知道访问网站名(最新的esni就在这里有用了[^18])。理论上不想让VPS处知道我们要请求的域名的话(浏览网站),可能需要在本地将DNS over HTTPS和ECH(Encrypted Client Hello)结合起来。说个题外话,在https网站访问时,代理服务器只能知道sni,而不知道通信的具体内容,https还是可以保证我们通信的安全性的。这是非对称密钥的特性决定的,代理服务器没有目标服务器上的私钥,所以无法解读我们在https数据中前主密钥(pre-master key),有兴趣的朋友可以看看有关https握手的相关材料,如rfc2818[^19]。
TCP数据流的转发是如何完成的?
我们这里特指的是TCP的数据流,这里应该就是Shadowsocks程序的核心部分了,虽然这里代码看起来是最快的,但是想描述清楚,尤其是体会到一些细节,还是挺复杂的。这里就不从代码出发,我们对数据流转发的过程做一个语言上的描述,针对一些概念用一些图表做一些解释,当把框架理清楚后,看代码就明白为什么这么设计了。下面的描述都是从sslocal程序的角度进行的,ssserver的流程我没看太细,但是大概有个概念,在数据流的转发行为上,二者应该是近乎一致。
在TCP数据流中,有两个可选模块,均是在配置文件中设置的,一个是fast open,这个先忽略不计,这是TCP层允许在连接握手过程中的SYN和SYN-ACK数据包中携带数据的一种改进,有兴趣的朋友可以看一看RFC7413[^21];另一个是一次性验证(One Time Auth),OTA因为流密码的特性容易被检测,已被废弃,参考[^20],原文讲的很好就不再摘抄了,故在分析源码时将其全部忽略。
在已经了解了事件的分发和处理过程后,数据流转发的核心就是TCPRelay.py了,这个py文件中主要有两个类TCPRelay和TCPRelayHandler,二者在事件分发过程中的关系前面已经记录过了,本节将侧重点放到两个类在数据转发过程中的行为。
在TCPRealy.py的开头,作者就已经给了一些描述,对于理解程序至关重要:
# for each opening port, we have a TCP Relay # for each connection, we have a TCP Relay Handler to handle the connection # for each handler, we have 2 sockets: # local: connected to the client # remote: connected to remote server # for each handler, it could be at one of several stages: # as sslocal: # stage 0 auth METHOD received from local, reply with selection message # stage 1 addr received from local, query DNS for remote # stage 2 UDP assoc # stage 3 DNS resolved, connect to remote 逐个连接 中继连接 # stage 4 still connecting, more data from local received # stage 5 remote connected, piping local and remote # as ssserver: # stage 0 just jump to stage 1 # stage 1 addr received from local, query DNS for remote # stage 3 DNS resolved, connect to remote # stage 4 still connecting, more data from local received # stage 5 remote connected, piping local and remote
意译过来:
对每个监听的端口,都有一个TCPRelay。
对每个连接,都用一个TCPRelayHandler来处理连接。
每个TCPRelayHandler,对应有2个套接字,TCPRelayHandler需要处理这二个套接字的IO事件:
本地套接字:连接到客户端
远端套接字:连接到远端服务器
对于每个TCPRelayHandler,它可能处于几个阶段之一:
作为sslocal:
阶段0:从本地接收到认证方法,回复选择消息 STAGE_INIT
阶段1:从本地接收到地址,为远端服务器查询DNS,获取远端服务器的ip地址(实际是ssserver) STAGE_ADDR
阶段2:UDP关联(UDP代理特有)STAGE_UDP_ASSOC
阶段3:DNS解析完成,连接到远端服务器 STAGE_DNS
阶段4:仍在连接中,从本地接收到更多数据 STAGE_CONNECTING
阶段5:远程已连接,作为本地套接字和远端套接字的中继管道 STAGE_STREAM
作为ssserver:
阶段0:直接跳转到阶段1
阶段1:从本地接收到地址,为远端服务器查询DNS(实际是目标站点)
阶段3:DNS解析完成,连接到远端服务器
阶段4:仍在连接中,从本地接收到更多数据
阶段5:远程已连接,作为本地套接字和远端套接字的中继管道
因此我们需要对命名约定进行更细致的描述。我把之前画的图再拿过来,接下来还要引用[^22]的部分。
命名约定与基本的事件状态
每一个 TCP 连接,都由一个 TCPRelayHandler 处理,而每一个 TCPRelayHandler 又都有两个套接字。下面是引用的图,图中的sock就是socket,也就是套接字。
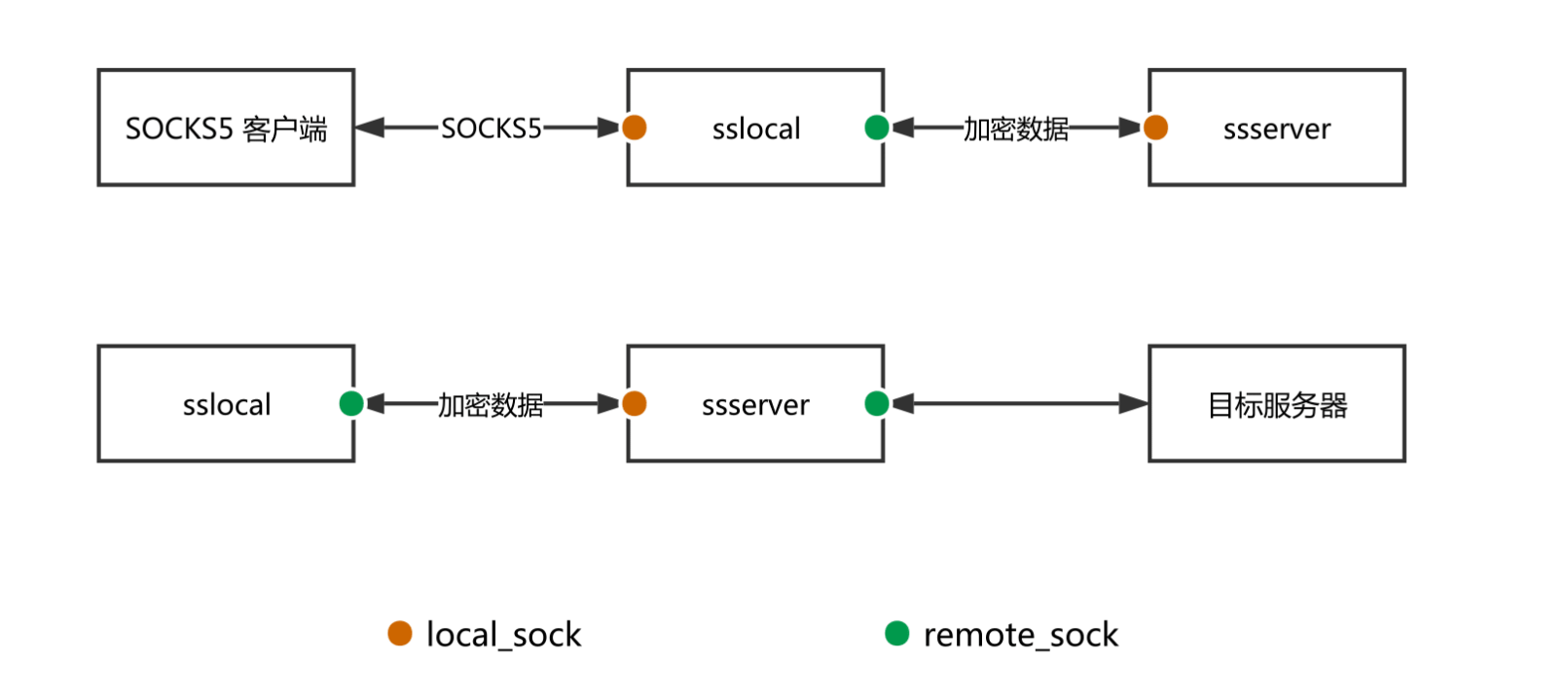
如图所示,黄色圆点表示
local_sock,绿色圆点表示remote_sock。
- 对于
sslocal而言,local指 SOCKS5 客户端,remote指ssserver;- 对于
ssserver而言,local指sslocal,remote指目标服务器;所以
local_sock就是专门负责与左边通信的套接字,remote_sock是专门负责与右边通信的套接字。另外,需要注意的是因为 shadowsocks 客户端和服务器重用了绝大部分的代码,所以在判断当前程序是当做sslocal还是ssserver用时会用一个变量is_local来判断,这里的local指的是sslocal。为了区分,「客户端」指
sslocal左边的 SOCKS5 客户端,「ss 客户端」指sslocal
除此之外,还需要明确对上行流和下行流的命名,以及对状态的定义,py文件中有如下的说明。
# for each handler, we have 2 stream directions: # upstream: from client to server direction # read local and write to remote # downstream: from server to client direction # read remote and write to local STREAM_UP = 0 STREAM_DOWN = 1 # for each stream, it's waiting for reading, or writing, or both WAIT_STATUS_INIT = 0 WAIT_STATUS_READING = 1 WAIT_STATUS_WRITING = 2 WAIT_STATUS_READWRITING = WAIT_STATUS_READING | WAIT_STATUS_WRITING
意译过来:
对每个TCPRelayHandler而言,有两个流(stream)的方向,对某个流的监听事件改变,实质上只会对local和remote套接字各自监听的一个状态(可读 or 可写)产生影响:
上行流:从客户端到服务器方向
状态改变只影响:是否从本地(local)读取和是否写入远端(remote)
下行流:从服务器到客户端方向
状态改变只影响:是否从远端(remote)读取和是否写入本地(local)
STREAM_UP = 0
STREAM_DOWN = 1对每个流来说,它等待读,等待写,或者既等待读又等待写
WAIT_STATUS_INIT = 0
WAIT_STATUS_READING = 1
WAIT_STATUS_WRITING = 2
WAIT_STATUS_READWRITING = WAIT_STATUS_READING | WAIT_STATUS_WRITING
流的三种状态会对应到(local socket和remote socket)作为组合的三种监听事件

我们取sslocal程序的做了个图进行说明。以上行流的三个状态为例,说明对(local socket和remote socket)监听事件的影响。其中I是IN的缩写,是可读事件;O是OUT,是可写事件。
| 上行流的状态 | (local socket,remote socket)的监听事件 |
|---|---|
| WAIT_STATUS_READING 等待读 | (I,-)只监听local套接字的可读,不监听remote套接字的事件 |
| WAIT_STATUS_WRITING 等待写 | (-,O)不监听local套接字的事件,只监听remote套接字的可写 |
| WAIT_STATUS_READWRITING 等待读写 | (I,O)既监听local套接字的可读,也监听remote套接字的可写 |
而对于下行流,也是类似:
| 下行流的状态 | (local socket,remote socket)的监听事件 |
|---|---|
| WAIT_STATUS_READING 等待读 | (-,I)不监听local套接字的事件,只监听remote套接字的可读 |
| WAIT_STATUS_WRITING 等待写 | (O,-)只监听local套接字的可写,不监听remote套接字的事件 |
| WAIT_STATUS_READWRITING 等待读写 | (I,O)既监听local套接字的可写,也监听remote套接字的可读 |
而在一个TCPRelayHandler中,同时需要维护STREAM_UP和STREAM_DOWN两个状态,local socket和remote socket实际监听的事件,是二者的或事件,比如对上行流的等待读和下行流的等待读,那么对(local socket,remote socket)的监听事件就是(I,-)|(-,I)=(I,I) ,用表格说明:
| (上行流,下行流)的状态 | (local socket,remote socket)的监听事件 |
|---|---|
| (R,R)(等待读,等待读) | (I, I) 监听local套接字的可读,监听remote套接字的可读 |
| (W,R)(等待写,等待读) | ( , IO) 不监听local套接字的事件,监听remote套接字的可读和可写 |
| (RW,R) (等待读写,等待读) | (I, IO) 监听local套接字的可读,监听remote套接字的可读和可写 |
| (R, W)(等待读,等待写) | (IO, ) 监听local套接字的可读和可写,不监听remote套接字的事件 |
| (W, W)(等待写,等待写) | (O, O) 监听local套接字的可写,监听remote套接字的可写 |
上表是方便理解的一个说法,实际上所有监听的事件都还要与POLL_ERR事件进行或运算,比如:( , IO) 表示 self._local_sock 监听 POLL_ERR 事件,self._remote_sock 监听 POLL_IN | POLL_OUT | POLL_ERR 事件,但是ERR事件不是数据转发过程中关注的重点,在后面的分析过程中先忽略掉它的存在和回调处理。
需要注意的是,在回调 _handle_dns_resolved 之前,也就是DNS查询还没有成功时,self._remote_sock 的值为 None,这是因为还不知道远端的ip地址,无法与远端进行连接,这时remote socket还没有创建。这时候流状态的改变不会影响 remote socket的监听事件。
更新流的函数实现如下:
class TCPRelayHandler(object):
def _update_stream(self, stream, status):
# update a stream to a new waiting status
# check if status is changed
# only update if dirty
dirty = False
if stream == STREAM_DOWN:
if self._downstream_status != status:
self._downstream_status = status
dirty = True
elif stream == STREAM_UP:
if self._upstream_status != status:
self._upstream_status = status
dirty = True
if not dirty:
return
if self._local_sock:#本地套接字 只关心下行流的写入 和 上行流的读取
event = eventloop.POLL_ERR
if self._downstream_status & WAIT_STATUS_WRITING:
event |= eventloop.POLL_OUT
if self._upstream_status & WAIT_STATUS_READING:
event |= eventloop.POLL_IN
self._loop.modify(self._local_sock, event)#修改监听事件
if self._remote_sock:#远端套接字 只关心下行流的读取 和 上行流的写入
event = eventloop.POLL_ERR
if self._downstream_status & WAIT_STATUS_READING:
event |= eventloop.POLL_IN
if self._upstream_status & WAIT_STATUS_WRITING:
event |= eventloop.POLL_OUT
self._loop.modify(self._remote_sock, event)
程序实现逻辑很容易理解:当更新上行流或下行流的事件时,会先检查这个流的状态是否发生了改变,没有改变就直接返回。当发生改变时,就会考虑改变后的流状态和另一条的流状态(另一条流的状态不会被更新),按照或运算,修改local socket和remote socket的监听事件。这里的等待读是0b01,等待写是0b10,读写是0b11,因此可以进行self._upstream_status & WAIT_STATUS_WRITING这样的运算,来修改监听事件。
对事件状态的理解及相关的代码
针对(上行流,下行流)状态的表格,我们需要对Shadowsocks可能出现的这五种状态的出现情景和状态改变发生的条件进行分析。(这些分析只是脑补的,没有实际调试程序验证,仅供个人理解回顾)
实际上,为了让分析更容易理解,应当根据remote套接字是否出现(也就是是否进入阶段4:STAGE_CONNECTING状态),将分析分为两个阶段。
- 当remote socket = None时
那么local socket有两种状态:不监听IO,I或者IO,而IO应该是正常情况不会出现的。
在TCPRelayHandler初始化时,local socket作为新建立的连接套接字,只监听In事件,用于接收socks5的握手信息。流状态设置为上行流等待读,下行流无,这时候TCPRelayHandler的状态处于阶段0:STAGE_INIT,等待从本地接收到认证方法,回复选择消息。
class TCPRelayHandler(object):
def __init__(self, server, fd_to_handlers, loop, local_sock, config,dns_resolver, is_local):
loop.add(local_sock, eventloop.POLL_IN | eventloop.POLL_ERR,self._server)
self._upstream_status = WAIT_STATUS_READING
self._downstream_status = WAIT_STATUS_INIT
self._stage = STAGE_INIT
当到socks5的握手信息发送过来,local socket的In事件发生,会触发TCPRelayHandler的handle_event回调函数,进而调用_on_local_read函数,读取状态后调用_handle_stage_init函数,回复握手消息并进入阶段1:STAGE_ADDR。此时仍是上行流等待读,监听local socket的In事件。
class TCPRelayHandler(object):
def _on_local_read(self):
data = self._local_sock.recv(BUF_SIZE)
if is_local and self._stage == STAGE_INIT:
self._handle_stage_init(data)
def _handle_stage_init(self, data):
self._write_to_sock(b'\x05\00', self._local_sock)
self._stage = STAGE_ADDR
握手阶段结束后,TCPRelayHandler等待建立连接请求,以获得最终目的服务器的地址。
当到socks5的握手信息发送过来,local socket的In事件发生,会触发TCPRelayHandler的handle_event回调函数,进而调用_on_local_read函数,读取状态后调用_handle_stage_addr函数,裁剪出shadowsocks中sslocal与ssserver传递最终目的服务器的数据头,(local程序还要根据sock5对client回复建立连接消息),将目前接收到的要发送到远端的数据存入缓存_data_to_write_to_remote列表中,向DNSResolver提交要连接的remote端的地址(local解析的是ssserver地址,ssserver要解析的最终目标服务器的地址)查询请求,并注册查询结束的回调函数。这时进入阶段3:STAGE_DNS。此时要修改上行流为等待写,实际上不监听local socket的读写事件,remote socket还没有建立,也不监听其事件。此时TCPRelayHandler 处于空闲状态,直到 DNS 解析完成, self._handle_dns_resolved 被回调后,才会进一步运行。不将local socket(应用客户端)进一步发过来的数据读入应用程序缓存中,这样如果DNS解析失败 ,不能与remote端建立连接,也不会无谓的消耗系统资源。这是我在学习TCP代理中继过程中,体会到最妙的事情之一,专门加个红字说明,谨记在心。
class TCPRelayHandler(object):
def _handle_stage_addr(self, data):
if cmd == CMD_CONNECT:
# just trim VER CMD RSV
data = data[3:]
header_result = parse_header(data)
addrtype, remote_addr, remote_port, header_length = header_result#拿到了远端地址端口 可能是域名
self._remote_address = (common.to_str(remote_addr), remote_port)
self._update_stream(STREAM_UP, WAIT_STATUS_WRITING)
self._stage = STAGE_DNS
if self._is_local:
self._write_to_sock((b'\x05\x00\x00\x01'b'\x00\x00\x00\x00\x10\x10'),self._local_sock)
data_to_send = self._encryptor.encrypt(data)
self._data_to_write_to_remote.append(data_to_send)
self._dns_resolver.resolve(self._chosen_server[0],self._handle_dns_resolved)#对本地 解析的是服务器的ip 也就是_chosen_server[0]
else:
if len(data) > header_length:
self._data_to_write_to_remote.append(data[header_length:])#把头长度去了 后面的数据流都是要转发的原始数据流
self._dns_resolver.resolve(remote_addr,self._handle_dns_resolved)#解析的是远端的地址 也就是目标服务器的地址
def _on_local_read(self):
data = self._local_sock.recv(BUF_SIZE)
if (is_local and self._stage == STAGE_ADDR) or (not is_local and self._stage == STAGE_INIT):
self._handle_stage_addr(data)
针对_handle_stage_addr函数,[^22]有一个很好的图,直观说明其功能。
其中,有向箭头表示数据流,虚线表示保存到缓冲区,蓝线表示进行 DNS 查询,橘黄色的框表示数据已经进行了加密,绿色的框表示数据已经进行了解密。在执行完
_handle_stage_addr以后,状态转移到了STAGE_DNS,同时对self._update_stream(STREAM_UP, WAIT_STATUS_WRITING)的调用,使得当前的TCPRelayHandler停止监听任何事件。也就是说,从现在开始,TCPRelayHandler啥也不管了,直到 DNS 解析完成,调用self._handle_dns_resolved再继续干活。
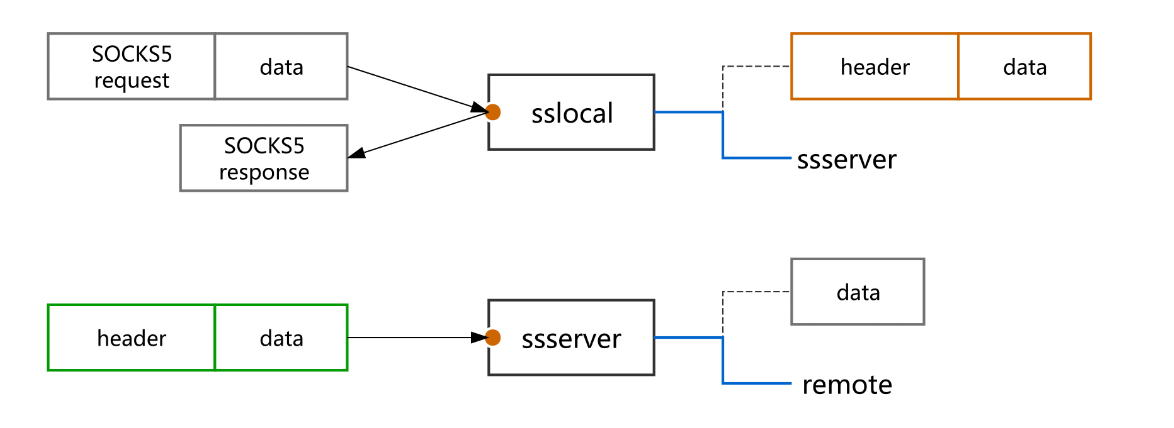
值得一提的是sslocal向ssserver传递最终目的地地址和端口的数据是在此时完成的,将sock5建立连接报文的前三个区域去除data = data[3:],作为ss的header。
sock5建立连接
+----+-----+-------+------+----------+----------+
|VER | CMD | RSV | ATYP | DST.ADDR | DST.PORT |
+----+-----+-------+------+----------+----------+
| 1 | 1 | 1 | 1 | Variable | 2 |
+----+-----+-------+------+----------+----------+裁剪后的数据格式如下:
+------+----------+----------+------+
| ATYP | DST.ADDR | DST.PORT | DATA |
+------+----------+----------+------+
| 1 | n | 2 | m |
+------+----------+----------+------+这就是sslocal发给sserver除去解密的初始向量外,最开始的几个字节,以指示ssserver远端,也就是最终目的地的地址。
在正常情况下,从stage0-stage3的过程中,local socket的监听事件从开始的In到最后的不监听;而在这个过程中,如果向local socket写入失败或不完全(正常前两阶段TCP缓存应该不会满,其他出现异常的可能不太清楚),会因为_write_to_sock函数,监听下行流的等待写状态,也就会出现local socket监听In和Out事件,写入完成后,也会回到正常的事件状态。
class TCPRelayHandler(object):
def _write_to_sock(self, data, sock):
#写不完 才监听可写 这是运用了非阻塞套接字的特效
#不在没写入时 就监听可写 这样会loop一直自循环
# write data to sock
# if only some of the data are written, put remaining in the buffer
# and update the stream to wait for writing
uncomplete = False
try:
l = len(data)
s = sock.send(data)#它返回一个整数值,表示实际发送的字节数
if s
- 当DNS解析完成时,
_handle_dns_resolved被回调,remote socket 创建
DNS解析得到了remote端的地址,这时会进入STAGE4:STAGE_CONNECTING,这是整个连接处理周期,(local socket,remote socket)唯一出现(I, IO) 的情况(忽略TCP fast open),在py文件的备注中也写明了这么做的目的:仍在连接中,从本地接收到更多数据。这时上行流是既等待读又等待写,因为远程的地址已经解析完成,正常情况下应该可以与远端通信,这时local socket的可读(即client在socks5传输阶段发来的数据)会调用_on_local_read函数,读取状态后调用_handle_stage_connecting函数。我们通过从local socket套接字读取数据,不发送而存到_data_to_write_to_remote缓存中,这样当remote socket可写时,就能直接写入remote socket,降低处理时间。而这个过程中出现错误,比如远端将TCP链接RST了,则在loop下一轮poll时,会按照error事件,将整个TCPRelayHandler销毁掉(通过python的引用计数机制,这个后面再详细说明,这里仅作抛砖引玉)。
class TCPRelayHandler(object):
def _handle_dns_resolved(self, result, error):
ip = result[1]#local server是ip直接拿到就是ip地址
self._stage = STAGE_CONNECTING
remote_addr = ip#local对应于server的ip 是在handle——addr里设置的
if self._is_local:
remote_port = self._chosen_server[1]
else:
remote_port = self._remote_address[1]
remote_sock = self._create_remote_socket(remote_addr,remote_port)
remote_sock.connect((remote_addr, remote_port))
self._loop.add(remote_sock,eventloop.POLL_ERR | eventloop.POLL_OUT,self._server)#进入监听remote socket的可写状态
self._stage = STAGE_CONNECTING
self._update_stream(STREAM_UP, WAIT_STATUS_READWRITING)#remote:io local:in
self._update_stream(STREAM_DOWN, WAIT_STATUS_READING)
直到remote socket 可写(OUT)事件发生,也就是remote端发送回来数据,回调函数调用_on_remote_write函数,进入最后一个阶段,阶段5:STAGE_STREAM。这时如果_data_to_write_to_remote中数据一次写完,状态是(I,I),没有写完,则状态是(-,IO)。
class TCPRelayHandler(object):
def handle_event(self, sock, event):
if sock == self._remote_sock:
if event & eventloop.POLL_OUT:
self._on_remote_write()
def _on_remote_write(self):
# handle remote writable event
self._stage = STAGE_STREAM
if self._data_to_write_to_remote:
data = b''.join(self._data_to_write_to_remote)
self._data_to_write_to_remote = []
self._write_to_sock(data, self._remote_sock)
else:
self._update_stream(STREAM_UP, WAIT_STATUS_READING)#等待local来
进入STAGE5:STAGE_STREAM后,local socket和remote socket已经就绪,这时TCPRelayHandler本质上就扮演一个TCP中继的角色。需要注意的是,TCP
是全双工的,也就是通信双方可以同时进行双向数据传输并且这两个方向的数据传输是独立的、同时进行的,所以可以将上行流下行流分开独立看待。这时(local socket,remote socket)的监听事件,会在(I,I),(-,IO),(IO,-)和(O,O)之间转换。想要理解这个时候的套接字监听事件的变化规则,就一定要深刻理解前面分析的上行流和下行流的概念!!!在作为TCP中继时,一条流上只能监听一个状态,要么等待读,要么等待写,以上行流为例,在这个阶段,要么监听local socket的IN事件,要么监听remote socket的OUT事件。这是因为,如果remote套接字没有一次写完,而还要从local socket读取数据到应用缓存中,数据来不及发送,可能会造成内存耗尽,需要等这一次的数据写完后,再进行从local socket的下一次读取。 没有数据要发送给需要写入的一端时,这条流就要回到等待读状态。仍以上行流为例,当读取的数据都一口气顺利发给remote socket或者_data_to_write_to_remote为空时,需要监听local socket的IN事件,而不监听remote socket的OUT事件。这是因为,当没有数据要写给remote socket时,remote socket正常应该就是可写的,如果还监听其OUT事件,在loop每次poll拉取事件时,都会有这个事件,造成Busy loop,即在计算机程序中一种浪费CPU周期的循环结构。[^ 23]
将代码简化后,一目了然:
class TCPRelayHandler(object):
def _on_local_read(self):
data = self._local_sock.recv(BUF_SIZE)
if self._stage == STAGE_STREAM:
self._handle_stage_stream(data)#写向远端 是local的读 所以要写向远端 未写完 存入列表并监听remote的out可写事件
return
def _on_remote_write(self):
self._stage = STAGE_STREAM
if self._data_to_write_to_remote:
data = b''.join(self._data_to_write_to_remote)
self._data_to_write_to_remote = []
self._write_to_sock(data, self._remote_sock)
else:
self._update_stream(STREAM_UP, WAIT_STATUS_READING)#等待local来
def _on_remote_read(self):
data = self._remote_sock.recv(BUF_SIZE)
self._write_to_sock(data, self._local_sock)
def _on_local_write(self):
if self._data_to_write_to_local:
data = b''.join(self._data_to_write_to_local)#数据流
self._data_to_write_to_local = []
self._write_to_sock(data, self._local_sock)#没写完 会整合成列表第一个元素 直到写完 才会监听remote的in
else:
self._update_stream(STREAM_DOWN, WAIT_STATUS_READING)#等待remote 可读 传来下行数据
def _handle_stage_stream(self, data):
self._write_to_sock(data, self._remote_sock)
def _write_to_sock(self, data, sock):
uncomplete = False
l = len(data)
s = sock.send(data)#它返回一个整数值,表示实际发送的字节数
if s
其中,remote socket和local socket的In/Out事件,间接触发的四个函数_on_local/remote_write/read(事件的处理有写从如何从handle_event到这四个函数),核心都是_write_to_sock函数。_write_to_sock函数,实现的是非阻塞的套接字写入方法,如果完全写入参数传入的套接字,就修改这条流为等待读状态,将监听事件转换为读取侧的可读事件;如果写入不完全,就修改这条流的状态为等待写状态,将监听事件转换为写入测的可写事件,不监听读取测的读取事件。直到列表_data_to_write_to_local待写入数据为空,由_on_XXX_write函数将这条流的状态变更为等待读状态,读取这条流上游传来的下一条信息。而在整个过程中,_on_XXX_read,读取数据时,都会尝试向另一端写入数据,写入成功或失败,都会按前面的逻辑进行。
在这里核心的TCP中继程序中,非阻塞IO套接字是灵魂,读取后的尝试写入成功与否,部分写入,都不会将整体程序阻塞住;而读的一条数据,只有全部发送完,才会再读取下一条数据,这样一个TCPRelayHandler处理中缓存就不会超过两个BUF_SIZE=32 * 1024(向local和remote两个套接字发送),可以在低性能机器上很好的运行。这也加深了对反应器模型的理解:IO多路复用机制获得事件+非阻塞套接字处理事件。好像领悟到了一点点皮毛,收益匪浅。
事件状态转换图
这个应该是写这篇blog时,最具有挑战性的一部分了,灵感源于[^22]的图,我个人觉得并不直观且不完整,甚至有描述不准确的地方,所以准备重画一个,先将[^22]的图放上,折叠起来。
>
[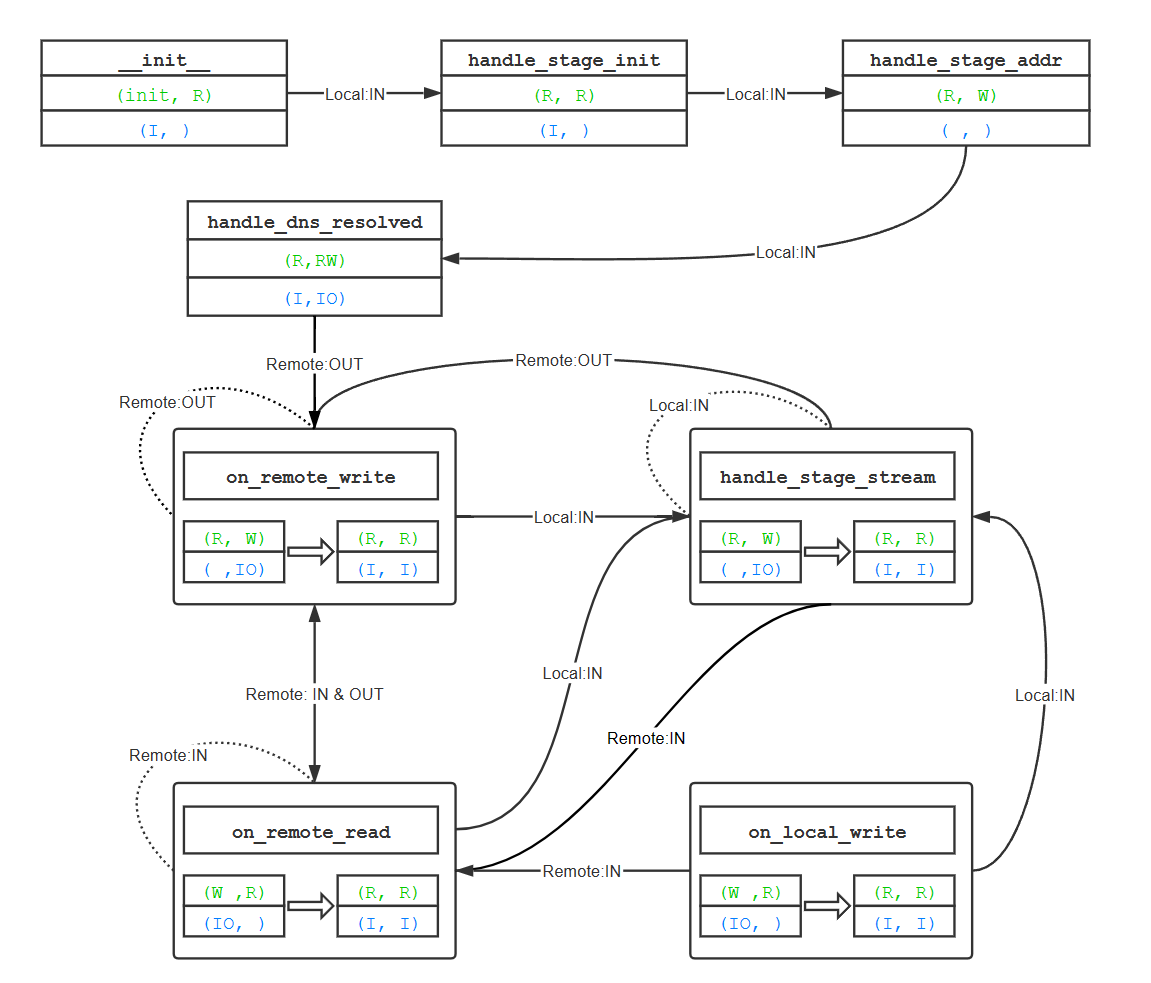](https://www.jcy1998.com/wp-content/uploads/2024/01/image-20240112114057351.png)
>
>- 绿色二元组:表示 self._downstream_status 和 self._upstream_status 分别对应的值;
>
>- 蓝色二元组:表示 self._local_sock 和 self._remote_sock 分别监听的事件,如果为空表示没有监听任何事件;
>
>- 实线箭头:表示在下一次事件循环中,如果给定的套接字发生给定的事件,那么会调用哪个函数,比如:
>
> handle_stage_init -> Local:IN -> handle_stage_addr
>
> 表示在调用完 _handle_stage_init 之后的下一次事件循环中,如果 self._local_sock 发生了可读事件,那么 _handle_stage_addr 会被调用;
>
>- 虚线:与实线箭头一样,只不过目标是自身;
>
>- 方框内的空心箭头:表示 self._write_to_sock 如果没有全部写成功时,可能发生的变化。
>
>上图只是 sslocal 的事件-状态变化图,ssserver 的又略有不同,不过这些都不重要,只要弄明白了每个阶段(stage)分别是干嘛的,对应的监听事件应该怎么变化,就自然而然的明白,能够看懂上图了。
我认为该图少了(O,O)状态,并且”方框内的空心箭头:表示 self._write_to_sock 如果没有全部写成功时,可能发生的变化“的表述有误,没有写完应该是继续监听该套接字的写状态,也就是Out事件,不会在空心箭头右方出现(I,I)事件,要不就会不停读入内存,导致内存占用过大(相关分析前文已描述)。这里只是我个人的一点想法,并不一定准确,如果有人看到的话,务必自己再理清思路思考一下。
与上图一致,从sslocal的角度作图,有机会再做sserver的图。
一个client想通过sock5代理其流量,首先会向sslocal监听的端口发起TCP连接,事件分发由loop完成,分发到TCPRelay实例,TCPRelay在欢迎套接字接受后,新建一个TCPRelayHandler实例用来处理连接套接字,来处理这条连接的数据流,也就是开始socks5的握手环节。我们的转换图就从TCPRelayHandler新建后开始,以五个阶段STAGE:0,1,3,4,5为标题(其中2是udp代理这里用不到),以TCPRelayHandler.handle_event函数分发到的四个函数_on_local/remote_write/read为起点,进行状态图的绘制。
picture1
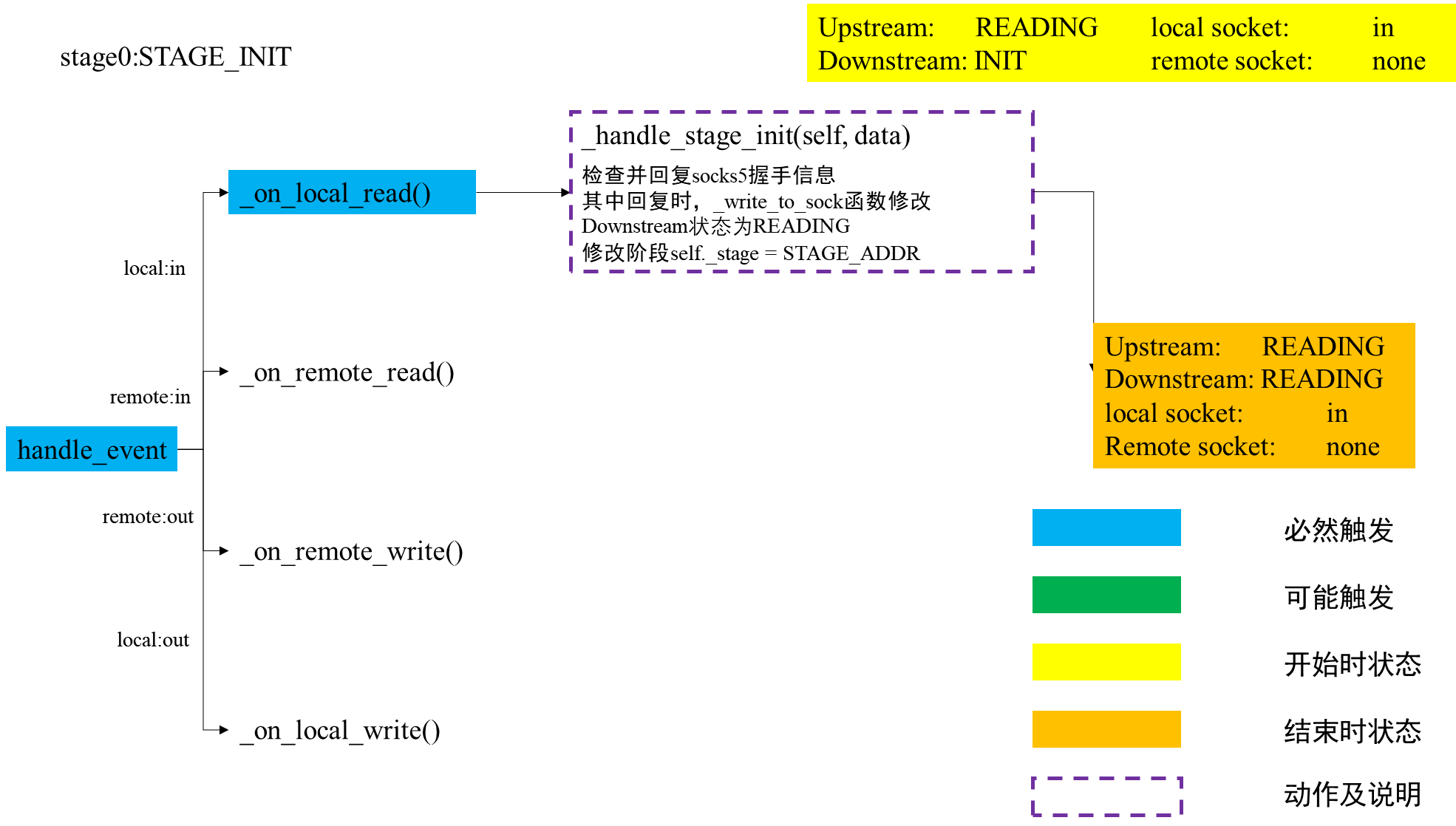
picture2
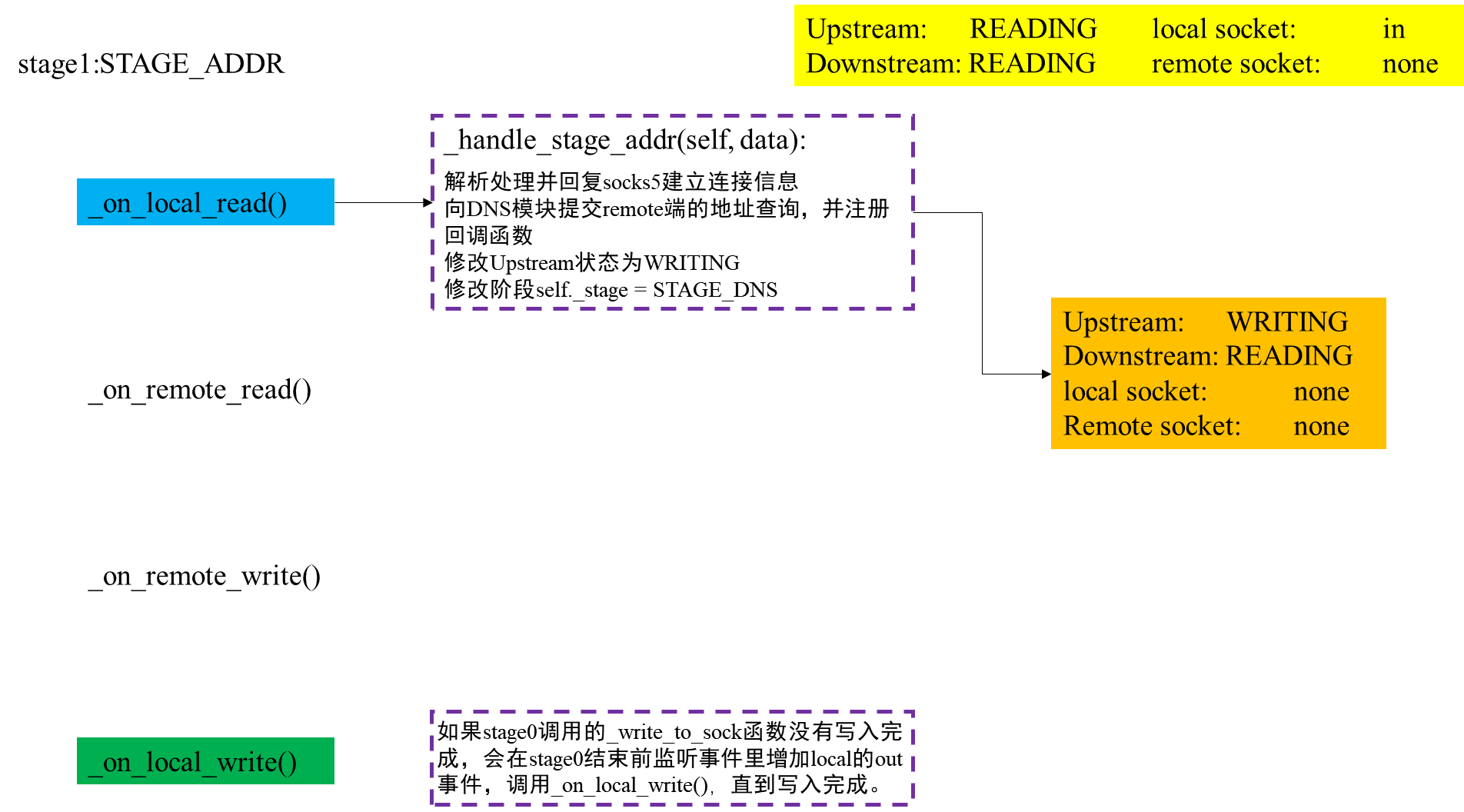
picture3
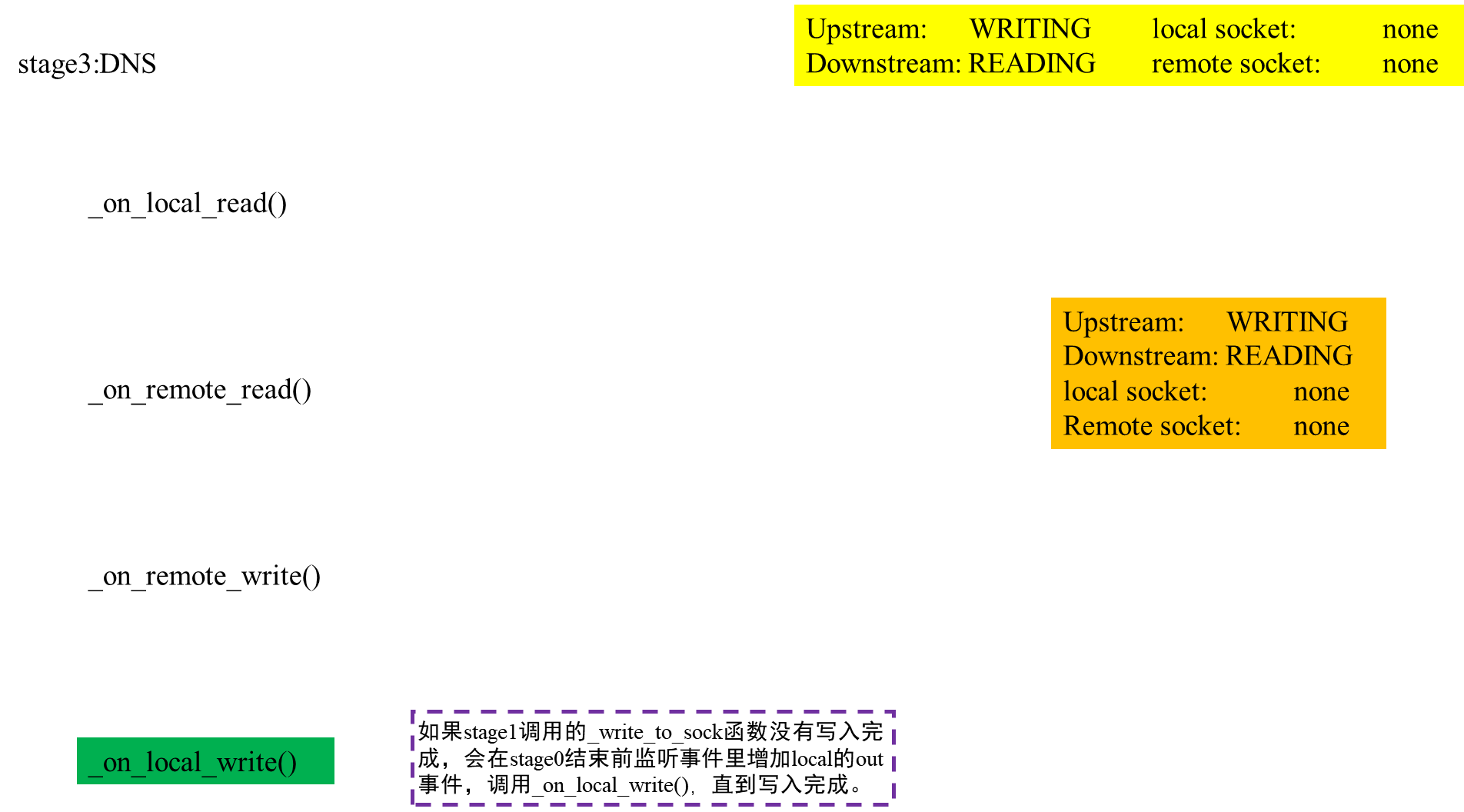
picture4
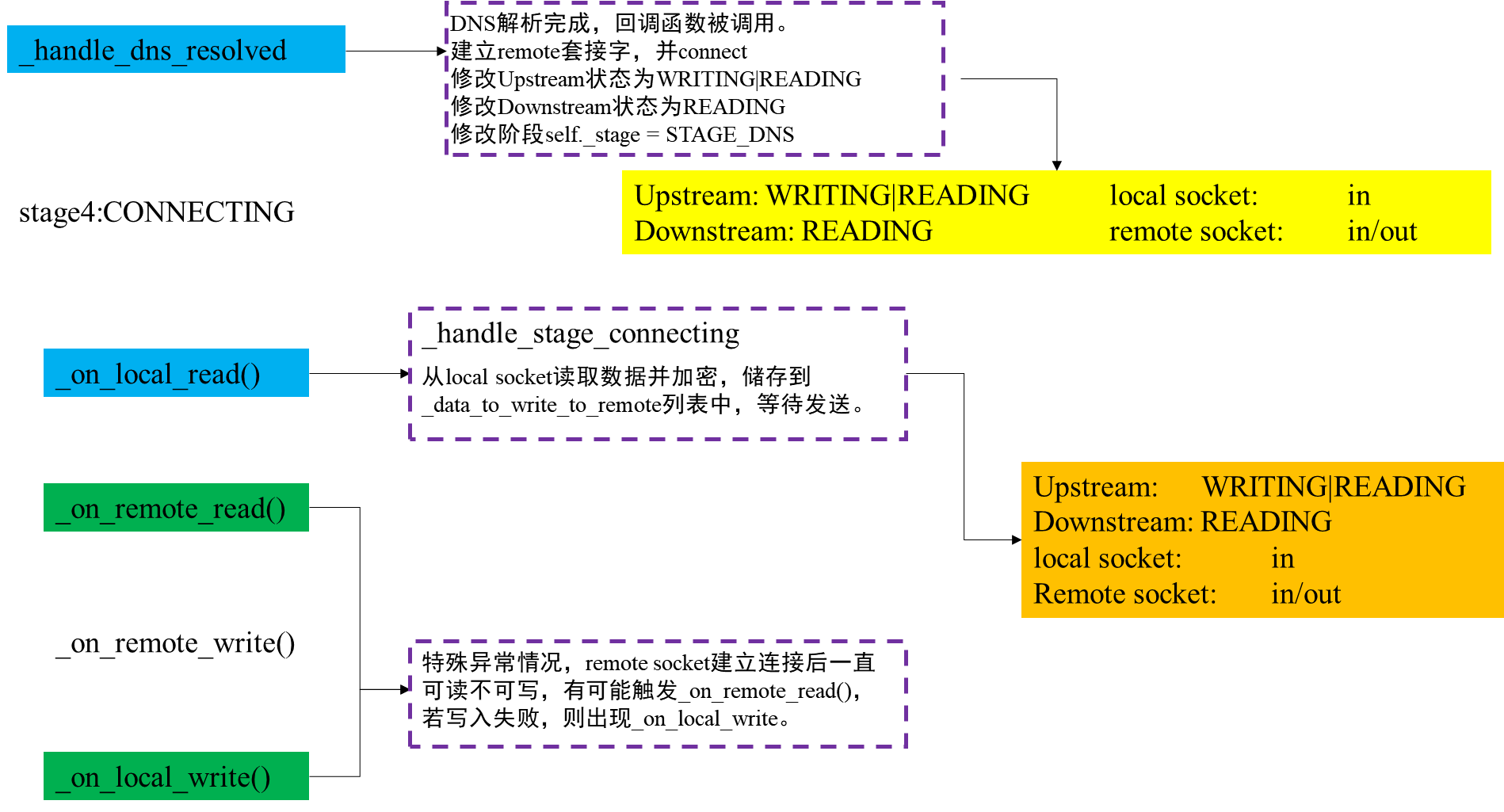
picture5
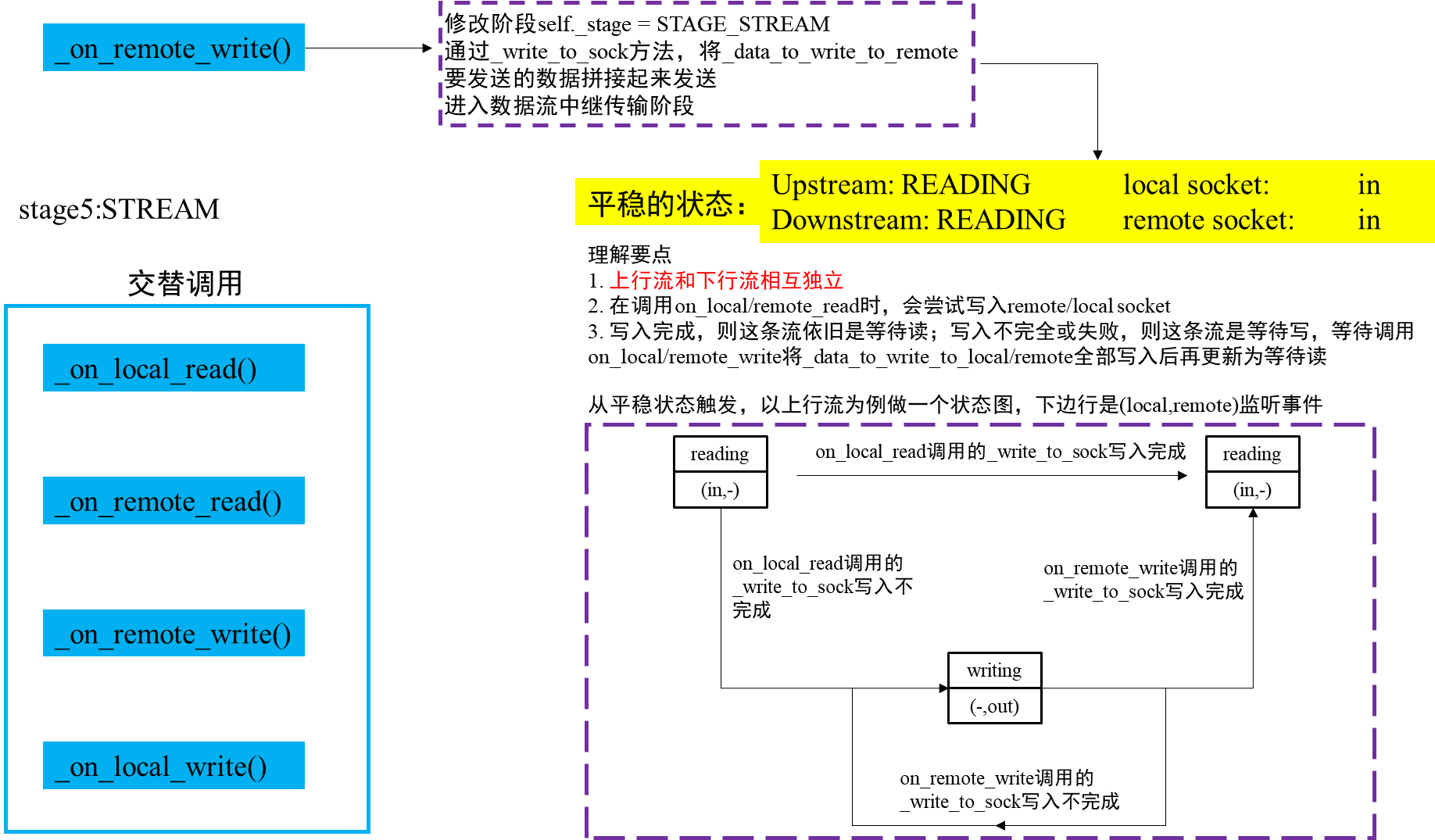
从结果上看,我感觉做的形式上远不如之前引用的那个图....先搁置吧....
置于第五阶段STREAM的理解,画出了上行流的状态图,下行流的状态图和它一致。二者组合起来的理解,我脑子里第一个反应可能有点怪异,但是写出来分享一下。认为这个上行流的状态图是一个列向量status,那么下行流的状态图就是它的转置status',实际这个stage5的套接字监听就是矩阵total_status=status*status‘,其中元素相乘时,套接字监听的是相乘元素的或事件。这样分析一个列向量就可以很好的把握矩阵的性质。如果做成引用图那种最终的实际状态,反而会十分杂乱而不得要领。这么一想,感觉上还有点像毕业做多元不确定性分析时的降维方法...
至于加解密,只要把握sslocal和ssserver通信时,数据先经过self._encryptor.encrypt(data)加密,ssserver和sslocal接收到彼此的数据时,通过self._encryptor.decrypt(data)解密,就可以很好的理解程序。
本身想在这之后,专门拿一节分析代码,但是好像之前都分析完了。有点懵逼,这一节就这么过去吧。到达这里,一条TCP数据流是如何完成寻址和代理转发的,就已经成为已解决的问题了,后面的部分还没记录,慢慢写,就先到这里了。
Written by a mechanics major student who is unemployed upon graduation
[^1]: 计算机网络:自顶向下方法 第八章:计算机网络中的安全
[^2]: 事件驱动程序设计 - 维基百科,自由的百科全书 (wikipedia.org)
[^3 ]: Socket 之accept与三次握手的关系_accept 三次握手-CSDN博客
[^4 ]: 简单邮件传输协议 - 维基百科,自由的百科全书 (wikipedia.org)
[^5 ]: RFC 1928 - SOCKS Protocol Version 5 (ietf.org)
[^6]: RFC 1034 - Domain names - concepts and facilities (ietf.org)
[^7]: RFC 1035 - Domain names - implementation and specification (ietf.org)
[^8 ]: 【转】IO模型及select、poll、epoll和kqueue的区别 - 超级大熊 - 博客园 (cnblogs.com)
[^9]: 反应器模式 - 维基百科,自由的百科全书 (wikipedia.org)
[^11 ]: python - Validate a hostname string - Stack Overflow
[^12 ]: shadowsocks-analysis/shadowsocks/asyncdns.py at master · lixingcong/shadowsocks-analysis (github.com)
[^13]: 取证基础知识--字节序 - 网安 (wangan.com)
[^14]: 路由器交换机配置教程(项目式)P182 任务6.3 IPSEC
[^15]: RFC 4301 - Security Architecture for the Internet Protocol (ietf.org)
[^16]: RFC 4309 - Using Advanced Encryption Standard (AES) CCM Mode with IPsec Encapsulating Security Payload (ESP) (ietf.org)
[^17]: Shadowsocks 源码分析——协议与结构 (loggerhead.me)
[^18]: What is encrypted SNI? | How ESNI works | Cloudflare
[^19]: RFC 2818 - HTTP Over TLS (ietf.org)
[^20]: 为何 shadowsocks 要弃用一次性验证 (OTA) - PRIN BLOG (prinsss.github.io)
[^21]: RFC 7413 - TCP Fast Open (ietf.org)
[^ 22]: Shadowsocks 源码分析——TCP 代理 (loggerhead.me)
[^23 ]: Shadowsocks 源码分析 | Wu's Blog (gogim1.github.io)